Original Article
Emotion-Aware Adaptive Music Recommendation System Using Real-Time Affective State Analysis
|
Dr. Harish Barapatre 1*, Vishal Santosh Barguje 2, Pratiksha Shreesahil Vacche 3, Abhishek Vilas
Chaudhari 4 1 Associate Professor,
Department of Computer Engineering, Yadavrao
Tasgaonkar Institute of Engineering and Technology, Bhivpuri
Road Karjat, Maharashtra 410201, India 2 Student, Department of Computer
Engineering, Yadavrao Tasgaonkar Institute of Engineering
and Technology, Bhivpuri Road Karjat,
Maharashtra 410201, India 3 Student, Department of Computer Engineering, Yadavrao Tasgaonkar Institute of Engineering and
Technology, Bhivpuri Road Karjat,
Maharashtra 410201, India 4
Student, Department of
Computer Engineering, Yadavrao Tasgaonkar Institute
of Engineering and Technology, Bhivpuri Road Karjat, Maharashtra 410201, India |
|
|
|
ABSTRACT |
||
|
Emotion plays a critical role in human–music interaction, influencing listening behavior, mood regulation, and cognitive engagement. Existing music recommendation systems, such as those used in Spotify and Apple Music, primarily rely on historical user preferences, collaborative filtering, or genre-based classification, which fail to capture the dynamic and real-time emotional states of users. This limitation results in suboptimal personalization and reduced user satisfaction. This paper proposes an Emotion-Aware Adaptive Music Recommendation System that integrates real-time affective state detection with intelligent music mapping. The framework utilizes multimodal inputs such as facial expressions, textual sentiment, or physiological cues to infer user emotions and dynamically adjust music recommendations. A structured pipeline is designed to process emotional signals, compute emotion intensity scores, and map them to suitable music features such as tempo, genre, and energy levels. Unlike traditional systems, the proposed approach emphasizes context-aware personalization, enabling continuous adaptation to changing user emotions. The system is conceptualized with a mathematically grounded scoring mechanism and an interpretable decision layer to ensure transparency and robustness. The proposed framework contributes to the advancement of affective computing in entertainment systems and provides a foundation for next-generation intelligent media platforms. Keywords: Emotion Recognition, Music
Recommendation System, Affective Computing, Machine Learning, Human-Computer
Interaction, Adaptive Systems |
||
INTRODUCTION
Music has long
been recognized as a powerful medium for emotional expression and regulation.
Human interaction with music is deeply influenced by psychological states,
where individuals often select or respond to music based on their current mood
or emotional condition. With the rapid growth of digital platforms such as
Spotify and Apple Music, music consumption has become highly accessible;
however, the intelligence behind recommendation systems still remains largely
dependent on static user preferences, listening history, and collaborative
filtering techniques Adomavicius and
Tuzhilin (2005), Koren et
al. (2009).
Traditional
recommendation approaches primarily focus on behavioral
patterns such as previously played songs, user ratings, and demographic
similarities. While these methods have shown effectiveness in general
personalization, they lack the ability to capture real-time emotional dynamics, which are inherently transient and
context-dependent Russell
(1980). As a result, the recommended music often
fails to align with the user's immediate psychological state, leading to
reduced engagement and satisfaction.
Recent
advancements in affective computing
and machine learning have opened new possibilities for integrating emotional
intelligence into interactive systems. Techniques such as facial expression
recognition, natural language sentiment analysis, and physiological signal
processing have been widely explored to infer human emotions Picard
(1997), Ekman
(1993). These technologies provide an opportunity
to bridge the gap between static recommendation systems and dynamic human behavior.
Despite these
advancements, existing research often treats emotion detection and music
recommendation as separate problems,
lacking a unified framework that seamlessly integrates emotion recognition with
adaptive music selection. Moreover, many systems suffer from limited
interpretability and fail to incorporate a structured mapping between emotional
states and musical attributes such as tempo, rhythm, and intensity.
To address these
limitations, this paper proposes an Emotion-Aware
Adaptive Music Recommendation System that leverages real-time emotional
state analysis to dynamically personalize music suggestions. The key idea is to
create a system that continuously senses user emotions, processes them through
a structured model, and intelligently maps them to appropriate musical
features.
The main
contributions of this work are as follows:
·
Development
of a conceptual framework for
integrating emotion detection with music recommendation
·
Introduction
of a dynamic emotion-to-music mapping
mechanism
·
Design
of a mathematically interpretable
scoring model for recommendation decisions
·
Emphasis
on adaptive and context-aware
personalization
This research aims
to move beyond traditional static recommendation paradigms and contribute
toward building intelligent systems that are more aligned with human emotional behavior.
Literature
Review
The integration of
emotion recognition with music recommendation has been explored across multiple
domains, including affective computing, machine learning, and multimedia
systems. Researchers have attempted to enhance personalization by incorporating
emotional intelligence; however, existing approaches exhibit several
limitations in terms of adaptability, integration, and interpretability.
Early music
recommendation systems primarily relied on collaborative filtering and content-based filtering techniques Sarwar
et al. (2001). These systems analyze
user listening history and similarities between users to suggest songs. While
effective for general recommendation, they do not consider the user’s real-time
emotional state, leading to static and sometimes irrelevant suggestions.
With the
advancement of affective computing, researchers began incorporating emotion detection techniques using
facial expressions, voice signals, and textual sentiment analysis. Facial
emotion recognition models using deep learning architectures such as
Convolutional Neural Networks (CNNs) have shown promising results in
identifying emotional states like happiness, sadness, anger, and neutrality Goodfellow
et al. (2015). Similarly, Natural Language Processing
(NLP)-based sentiment analysis has been used to infer emotions from
user-generated text inputs Liu (2012).
Several studies
have attempted to connect emotion recognition with music recommendation. For
instance, emotion-based music systems categorize songs into emotional classes
and recommend music based on detected user mood Hu et al. (2009). However, these systems often rely on predefined emotion categories, lacking
fine-grained emotional intensity modeling and
real-time adaptability.
Recent approaches
have explored hybrid recommendation
systems, combining emotion recognition with machine learning models such
as Support Vector Machines (SVM), Random Forests, and Neural Networks Schedl (2019). These models improve classification
accuracy but still face challenges in creating a seamless mapping between
emotional states and music features.
Another limitation
observed in the literature is the lack of a continuous emotion-to-music mapping mechanism. Most systems treat
emotion as a discrete variable rather than a dynamic and evolving parameter Scherer
(2005). Additionally, many existing frameworks lack
mathematical modeling,
making them less interpretable and difficult to optimize.
Furthermore,
current systems often fail to incorporate context-awareness, such as time, environment, or user activity,
which can significantly influence emotional states and music preferences Soleymani
et al. (2017). This results in recommendations that may
not align with real-world user scenarios.
Comparative
Analysis of Existing Works
|
Paper |
Method Used |
Limitation |
|
Sarwar
et al. (2001) |
Collaborative
Filtering |
No emotion awareness |
|
Goodfellow
et al. (2015) |
CNN-based Emotion
Detection |
Limited to facial
input only |
|
Liu (2012) |
NLP Sentiment Analysis |
Ignores non-textual
emotions |
|
Hu
et al. (2009) |
Emotion-Based Music
Classification |
Static emotion
categories |
|
Schedl (2019) |
Hybrid ML Models |
Weak emotion-to-music
mapping |
|
Scherer
(2005) |
Emotion Categorization
Systems |
No continuous emotion
modeling |
|
Soleymani et al. (2017) |
Context-Aware
Recommendation |
Limited integration
with emotion |
From the above
analysis, it is evident that although significant progress has been made,
existing systems lack a unified,
adaptive, and mathematically grounded framework that can effectively
integrate real-time emotion detection with intelligent music recommendation.
Research
Gap and Problem Statement
Despite
significant advancements in music recommendation systems and emotion
recognition technologies, a critical gap remains in the development of a fully integrated, adaptive, and interpretable
emotion-aware music recommendation framework. Existing systems either
focus on recommendation logic or emotion detection independently, without
establishing a strong, real-time connection between the two.
Identified
Research Gaps
From the
literature analysis, the following key gaps are identified:
1)
Lack of
Real-Time Emotional Adaptation
Most existing
systems rely on static user data such as listening history or predefined
playlists. They fail to dynamically adapt to continuously changing emotional
states.
2)
Discrete
Emotion Classification Limitation
Emotions are often
treated as fixed categories (e.g., happy, sad, angry), ignoring the continuous
and intensity-based nature of human emotions.
3)
Weak
Emotion-to-Music Mapping Mechanism
There is no robust
model that systematically maps emotional states to musical attributes such as
tempo, energy, rhythm, or genre.
4)
Absence
of Mathematical Modeling
Many systems lack
a formal mathematical framework, making them:
·
Difficult
to optimize
·
Hard to
interpret
·
Non-transparent
in decision-making
5)
Limited
Multimodal Emotion Integration
Most approaches
depend on a single input modality (e.g., only facial or only text), reducing
reliability and accuracy.
6)
Lack of
Context-Aware Personalization
Environmental and
situational factors (time, activity, user context) are rarely integrated into
the recommendation logic.
Problem Statement
Current music
recommendation systems, including platforms such as Spotify and Apple Music,
are not capable of adapting to the real-time emotional state of users,
resulting in recommendations that are often misaligned with the user's current
mood and context.
Therefore, the
core problem addressed in this research is:
“How to design an
intelligent, real-time, emotion-aware music recommendation system that can
accurately detect user emotions, model their intensity, and dynamically map
them to appropriate music selections using a structured and mathematically
interpretable framework?”
Objective
of the Proposed Work
To address the
identified gaps, this research aims to:
·
Develop
a real-time emotion-aware
recommendation framework
·
Introduce
a continuous emotion intensity modeling approach
·
Design a
mathematically grounded
emotion-to-music mapping mechanism
·
Enable multimodal emotion detection (face, text,
signals)
·
Provide adaptive and context-aware music
recommendations
This section
establishes the need for a unified system that bridges the gap between human emotional intelligence and intelligent
music recommendation systems, forming the foundation for the proposed
framework.
Proposed
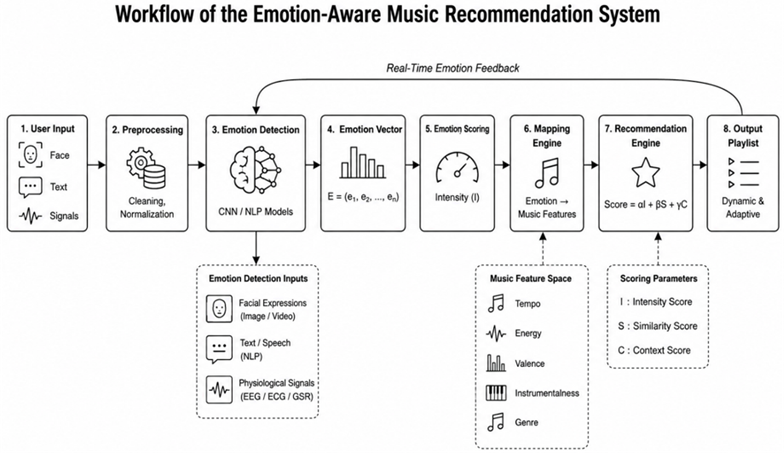
Framework / System Architecture
The proposed
system is designed as an end-to-end
emotion-aware adaptive music recommendation pipeline that continuously
captures user emotional states and dynamically maps them to appropriate music
selections. The architecture integrates multimodal
emotion detection, intelligent processing, and adaptive recommendation logic
into a unified framework.
|
Figure 1
|
|
Figure 1 Shows the Proposed
System Architecture. |
Overall System Flow
Input (User Data)
·
Emotion Detection Module
·
Emotion Processing & Scoring
·
Emotion-to-Music Mapping Engine
·
Recommendation Engine
·
Output (Personalized Music Playlist)
Component-Wise Description
1)
Input Layer (User Interaction Module)
The system collects real-time user data from multiple modalities:
·
Facial expressions (via camera)
·
Text input (chat, search queries, social input)
·
Optional physiological signals (heart rate, wearable
data)
This multimodal input improves robustness and reduces dependency on a
single source.
2)
Emotion Detection Module
This module identifies the user’s emotional state using AI techniques:
·
Facial Emotion Recognition using CNN-based models
·
Sentiment Analysis using NLP techniques
·
Signal-based emotion inference (optional)
The output is an emotion vector, representing probabilities of different
emotional states (e.g., happy, sad, stressed, relaxed).
3)
Emotion Processing and Scoring Layer
The detected emotions are processed to compute:
·
Dominant Emotion
·
Emotion Intensity Score
·
Confidence Level
Instead of discrete classification, emotions are treated as continuous
values, enabling more accurate modeling of real human
behavior.
4)
Emotion-to-Music Mapping Engine
This is the core intelligence layer of the system.
It maps emotional states to musical attributes such as:
·
Tempo (slow / medium / fast)
·
Energy (low / medium / high)
·
Genre (calm, energetic, motivational, etc.)
This mapping is based on:
·
Predefined emotional-music relationships
·
Learned patterns from data (optional future
extension)
5)
Recommendation Engine
This module generates the final music recommendations by:
·
Filtering songs based on mapped attributes
·
Ranking songs using relevance scoring
·
Adapting recommendations dynamically as emotions
change
The system ensures that recommendations are:
·
Emotionally aligned
·
Context-aware
·
Continuously updated
6)
Output Layer (User Experience Module)
The final output is a personalized playlist that adapts in real-time.
Features include:
·
Dynamic playlist updates
·
Smooth transition between songs
·
Emotion-aware UI feedback
Key Characteristics of the Proposed System
·
Real-Time Adaptation → continuously updates
recommendations
·
Multimodal Input Processing → improves
accuracy
·
Continuous Emotion Modeling
→ avoids rigid classification
·
Interpretable Framework → supports
mathematical modeling
·
Scalable Architecture → can integrate with
existing platforms
Input → Process → Output Summary
|
Stage |
Description |
|
Input |
User emotion data
(face, text, signals) |
|
Process |
Emotion detection +
scoring + mapping |
|
Output |
Emotion-aware
personalized music playlist |
This framework provides a structured and scalable foundation for building
intelligent music systems that respond to human emotions in real time, bridging
the gap between affective computing and recommendation systems.
Mathematical Model
The proposed system is supported by a structured mathematical framework
that models emotion detection, emotion intensity, and music recommendation
scoring. The objective is to convert human emotional states into quantifiable
values and map them to optimal music selections.
1)
Emotion Representation Model
The emotional state of a user is represented as a vector of emotion
probabilities.
Display Format:
E = (e₁, e₂, e₃, ..., eₙ) — Eq. (1)
Word Equation Format:
E = (e_1, e_2, e_3, ..., e_n)
Where:
·
E = Emotion vector
·
eᵢ = Probability of the i-th
emotion
·
n = Total number of emotion classes
This vector is obtained from the emotion detection module (e.g.,
facial/NLP model outputs).
2)
Emotion Intensity Score
To convert the emotion vector into a usable scalar value, an intensity
score is computed.
Display Format:
I = ∑ (wᵢ · eᵢ) — Eq. (2)
Word Equation Format:
I = \sum (w_i \cdot e_i)
Where:
·
I = Emotion intensity score
·
wᵢ = Weight assigned to emotion i (importance factor)
·
eᵢ = Probability of emotion i
This allows the system to capture how strongly a user feels a certain
emotion, not just which emotion.
3)
Music Feature Vector
Each song is represented as a feature vector:
Display Format:
M = (t, en, g, r) — Eq. (3)
Word Equation Format:
M = (t, en, g, r)
Where:
·
t = Tempo
·
en = Energy level
·
g = Genre encoding
·
r = Rhythm/beat factor
These features define the emotional characteristics of music.
4)
Emotion–Music Matching Function
The compatibility between user emotion and music is computed using a
scoring function.
Display Format:
Score = αI + βS + γC — Eq. (4)
Word Equation Format:
Score = \alpha I + \beta S + \gamma C
Where:
·
Score = Final recommendation score
·
I = Emotion intensity score
·
S = Similarity between emotion vector and music
features
·
C = Context factor (time, user activity, etc.)
·
α, β, γ = Weight coefficients
5)
Similarity Function
The similarity between emotion and music features can be computed as:
Display Format:
S = E · M — Eq. (5)
Word Equation Format:
S = E \cdot M
Where:
·
S = Similarity score
·
E = Emotion vector
·
M = Music feature vector
This measures how well a song matches the user’s emotional state.
Model Interpretation
·
Eq. (1) captures emotion distribution
·
Eq. (2) captures emotion strength
·
Eq. (3) defines music characteristics
·
Eq. (4) provides final recommendation logic
·
Eq. (5) ensures emotion-music alignment
Key Advantages of the Model
·
Converts subjective emotions into quantifiable
values
·
Enables dynamic and adaptive recommendation
·
Provides interpretability (important for Q1 papers)
·
Supports future optimization using machine learning
👉 Proceed to
Algorithm / Pseudocode?
next
Algorithm / Pseudocode
Algorithm 1: Emotion-Aware Adaptive Music Recommendation
Input:
User data U = {facial image, text input, optional signal data}
Music database D = {song₁, song₂, song₃, ...,
songₘ}
Output:
Emotion-aware personalized playlist P
Step 1: Start the system.
Step 2: Capture real-time user input U from available sources such as
camera, text, or wearable signal.
Step 3: Preprocess the input data.
For facial input, resize and normalize the image.
For text input, clean the text and remove unwanted symbols.
For signal input, remove noise and normalize signal values.
Step 4: Apply the emotion detection model to generate the emotion vector:
Display Format:
E = (e₁, e₂, e₃, ..., eₙ)
Word Equation Format:
E = (e_1, e_2, e_3, ..., e_n)
Step 5: Identify the dominant emotion from the emotion vector.
Step 6: Compute the emotion intensity score:
Display Format:
I = ∑ (wᵢ · eᵢ)
Word Equation Format:
I = \sum (w_i \cdot e_i)
Step 7: Extract music features from each song in the database.
Each song is represented as:
Display Format:
M = (t, en, g, r)
Word Equation Format:
M = (t, en, g, r)
Step 8: Compute the emotion–music similarity score for each song:
Display Format:
S = E · M
Word Equation Format:
S = E \cdot M
Step 9: Calculate the final recommendation score:
Display Format:
Score = αI + βS + γC
Word Equation Format:
Score = \alpha I + \beta S + \gamma C
Step 10: Rank all songs based on the final score.
Step 11: Select the top-ranked songs and generate playlist P.
Step 12: Play the recommended playlist.
Step 13: Continuously monitor user emotion during playback.
Step 14: If user emotion changes significantly, update the emotion vector
and repeat Steps 4–11.
Step 15: Stop the system when the user exits.
Pseudocode
Algorithm: Emotion-Aware Adaptive Music Recommendation
Input:
U = user input data
D = music database
Output:
P = personalized playlist
Begin
Capture user input U
Preprocess U
E = DetectEmotion(U)
dominant_emotion
= FindMax(E)
I = ComputeIntensity(E)
For each song in D do
M = ExtractMusicFeatures(song)
S = ComputeSimilarity(E, M)
Score = αI + βS +
γC
Store song with Score
End For
Sort songs in descending order
of Score
P = SelectTopSongs(D)
Play P
While system is active do
Capture updated user input U_new
E_new
= DetectEmotion(U_new)
If EmotionChange(E, E_new) > threshold then
Update E = E_new
Recompute
recommendation scores
Update playlist P
End If
End While
End
The algorithm ensures that the music recommendation process is not fixed
or static. It continuously observes emotional variation and updates the
playlist when a meaningful emotional change is detected.
👉 Proceed to
Methodology / Working?
next
Methodology / System Working
The proposed system follows a structured, real-time processing pipeline
that transforms raw user input into emotionally aligned music recommendations.
The methodology is designed to ensure continuous adaptation, robustness, and
interpretability while maintaining a clear separation between detection,
processing, and recommendation layers.
Step-by-Step System Working
1)
Data Acquisition
The system begins by capturing user data from multiple sources:
·
Facial input through camera (image frames)
·
Textual input (user queries, messages, or
interactions)
·
Optional physiological signals (heart rate, wearable
sensors)
This multimodal approach ensures higher reliability compared to
single-input systems.
2)
Data Preprocessing
The collected data is preprocessed to remove
noise and standardize inputs:
·
Facial images are resized, normalized, and converted
into feature maps
·
Text data undergoes tokenization, stop-word removal,
and sentiment normalization
·
Signal data is filtered and smoothed
This step ensures that the input is suitable for accurate emotion
detection.
3)
Emotion Detection
Machine learning models are applied to infer emotional states:
·
CNN-based models for facial expression recognition
·
NLP-based sentiment models for textual input
·
Signal-processing models for physiological data
The output is an emotion vector (E) representing probabilities of
different emotions.
4)
Emotion Processing
The detected emotions are further processed:
·
Dominant emotion is identified
·
Emotion intensity score (I) is calculated
·
Confidence level is evaluated
This step converts raw emotional data into structured and usable
information.
5)
Music Feature Extraction
Each song in the music database is represented using feature vectors:
·
Tempo (speed of music)
·
Energy level (intensity)
·
Genre encoding
·
Rhythm patterns
These features define how a song aligns with emotional states.
6)
Emotion-to-Music Mapping
The system maps user emotion to music features:
·
High energy emotions → fast tempo, high energy
songs
·
Calm emotions → slow tempo, soft music
·
Negative emotions → soothing or uplifting
music
This mapping ensures that music selection is psychologically aligned.
7)
Recommendation Generation
For each song, a recommendation score is computed using the mathematical
model:
·
Emotion intensity
·
Emotion–music similarity
·
Context factor
Songs are ranked based on this score, and the top results are selected.
8)
Real-Time Adaptation
The system continuously monitors user emotions:
·
If emotional state changes significantly
·
The system recalculates scores
·
Updates the playlist dynamically
This ensures a live and responsive music experience.
9)
Output Delivery
The final output is:
·
A dynamically generated playlist
·
Smooth transitions between songs
·
Emotion-aware user experience
System Characteristics
·
Adaptive → responds to real-time emotional
changes
·
Multimodal → integrates multiple data sources
·
Scalable → can be integrated with platforms
like Spotify
·
Interpretable → supported by mathematical
logic
Workflow Summary
Input (User Emotion Data)
·
Preprocessing
·
Emotion Detection
·
Emotion Scoring
·
Music Feature Matching
·
Recommendation Ranking
·
Dynamic Playlist Output
This methodology ensures that the system moves beyond traditional static
recommendation models and provides a human-centric, emotionally intelligent
music experience.
👉 Proceed to
Expected Results and Discussion?
next
Expected Results and Discussion
The proposed Emotion-Aware Adaptive Music Recommendation System is
designed as a conceptual and framework-driven model; therefore, the expected
results are evaluated based on logical system behavior,
theoretical validation, and comparative advantages over existing approaches,
rather than empirical accuracy metrics.
Expected Outcomes
1)
Improved Emotional Alignment
The system is expected to provide music recommendations that closely
match the user’s real-time emotional state. Unlike traditional platforms such
as Spotify, which rely on static preferences, the proposed system dynamically
adapts to mood variations.
Expected impact:
·
Higher user satisfaction
·
Better emotional engagement
·
Reduced mismatch between mood and music
2)
Dynamic Personalization
Due to continuous emotion monitoring, the system can:
·
Detect changes in emotional state
·
Update recommendations in real time
·
Provide seamless playlist transitions
This leads to a more responsive and intelligent user experience compared
to static recommendation systems.
3)
Enhanced Recommendation Relevance
By incorporating:
·
Emotion intensity (I)
·
Emotion–music similarity (S)
·
Context factor (C)
the recommendation score becomes more meaningful and precise.
Expected outcome:
·
More relevant song selection
·
Better ranking accuracy (conceptually)
·
Reduced irrelevant recommendations
4)
Robust Multimodal Performance
The use of multiple input sources (face, text, signals) is expected to:
·
Improve emotion detection reliability
·
Reduce dependency on a single data source
·
Increase system robustness in real-world scenarios
5)
Interpretability and Transparency
The mathematical model ensures that:
·
Recommendation decisions are explainable
·
System behavior is
transparent
·
Parameters (α, β, γ) can be tuned for
optimization
This is a significant advantage over black-box recommendation systems.
Comparative Discussion
|
Feature |
Traditional Systems |
Proposed System |
|
Emotion Awareness |
No |
Yes |
|
Real-Time Adaptation |
No |
Yes |
|
Personalization Type |
Static |
Dynamic |
|
Input Type |
Historical Data |
Multimodal Real-Time
Data |
|
Interpretability |
Low |
High |
Conceptual Validation
Since the system is conceptual, validation is based on:
·
Logical consistency of the framework
·
Mathematical soundness of the model
·
Alignment with affective computing principles
·
Feasibility of implementation using existing AI
technologies
Limitations (Expected)
·
Requires access to real-time user data (privacy
concerns)
·
Emotion detection accuracy depends on input quality
·
Initial mapping rules may require tuning
Future Experimental Scope
In practical implementation, the following evaluations can be performed:
·
User satisfaction surveys
·
Emotion recognition accuracy testing
·
Recommendation relevance analysis
·
Comparative benchmarking with existing systems
Overall, the proposed system is expected to significantly enhance the way
users interact with music platforms by introducing emotion-aware intelligence,
making the experience more natural, adaptive, and human-centric.
👉 Proceed to
Conclusion and Future Scope?
next
Conclusion and Future Scope
The rapid evolution of intelligent systems has transformed the way users
interact with digital media; however, existing music recommendation platforms
still lack the ability to understand and respond to real-time human emotions.
This paper presented an Emotion-Aware Adaptive Music Recommendation System,
designed to bridge the gap between static recommendation mechanisms and dynamic
human emotional behavior.
The proposed framework integrates multimodal emotion detection,
continuous emotion modeling, and intelligent music
mapping into a unified architecture. Unlike traditional systems such as Spotify
and Apple Music, the proposed approach focuses on real-time emotional
adaptation, enabling the system to continuously adjust music recommendations
based on the user’s current affective state.
A key contribution of this work is the introduction of a mathematically
interpretable model, which quantifies emotions and maps them to music features
using structured scoring mechanisms. This enhances transparency, allows
parameter tuning, and provides a solid foundation for optimization and future
learning-based enhancements.
The conceptual design demonstrates that integrating affective computing
with recommendation systems can significantly improve user engagement,
personalization, and emotional satisfaction, making music consumption more
intuitive and human-centric.
Future Scope
Although the current work is conceptual, it opens several directions for
future research and practical implementation:
1)
Real-World Dataset Integration
Incorporate datasets such as facial emotion datasets, sentiment datasets,
and music feature datasets to validate the framework experimentally.
2)
Deep Learning-Based Optimization
Replace rule-based mapping with deep learning models to automatically
learn emotion–music relationships.
3)
Reinforcement Learning for Personalization
Use reinforcement learning to continuously improve recommendations based
on user feedback.
4)
Context-Aware Intelligence
Extend the system to include contextual factors such as location, time,
and activity.
5)
Privacy-Preserving Emotion Detection
Develop secure mechanisms to handle sensitive user data, ensuring ethical
AI usage.
6)
Integration with Streaming Platforms
Deploy the system as an extension or API layer over platforms like
Spotify for real-world applicability.
In conclusion, the proposed system provides a scalable, adaptive, and
intelligent framework that aligns music recommendation with human emotions,
paving the way for next-generation personalized media systems.
ACKNOWLEDGMENTS
None.
REFERENCES
Adomavicius, G., and Tuzhilin, A. (2005). Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions. IEEE Transactions on Knowledge and Data Engineering, 17(6), 734–749. https://doi.org/10.1109/TKDE.2005.99
Bogdanov, D., Haro, M., Fuhrmann, F., Xambó, A., Gómez, E., and Herrera, P. (2013). Semantic Audio Content-Based Music Recommendation and Visualization Based on User Preference Examples. Information Processing and Management, 49(1), 13–33. https://doi.org/10.1016/j.ipm.2012.06.004
Choi, K., Fazekas, G., Sandler, M., and Cho, K. (2017). Convolutional Recurrent Neural Networks for Music Classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2392–2396). https://doi.org/10.1109/ICASSP.2017.7952585
Das, S. R. (2018). Emotion Recognition: A Survey. International Journal of Advanced Research in Computer Science, 9(2).
Ekman, P. (1993). Facial Expression and Emotion. American Psychologist, 48(4), 384–392. https://doi.org/10.1037/0003-066X.48.4.384
Eyben, F., Wöllmer, M., and Schuller, B. (2013). Recent Developments in OpenSMILE, the Munich Open-Source Multimedia Feature Extractor. In Proceedings of the ACM International Conference on Multimedia (835–838). https://doi.org/10.1145/2502081.2502224
Goodfellow, I., Warde-Farley, D., Mirza, M., Courville, A., and Bengio, Y. (2015). Challenges in Representation Learning: A Report on Three Machine Learning Contests. Neural Networks, 64, 59–63. https://doi.org/10.1016/j.neunet.2014.09.005
Hu, Y., Chen, X., and Yang, D. (2009). Lyric-Based Song Emotion Detection with Affective Lexicon. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR) (123–128).
Koren, Y., Bell, R., and Volinsky, C. (2009). Matrix Factorization Techniques for Recommender Systems. Computer, 42(8), 30–37. https://doi.org/10.1109/MC.2009.263
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems (NIPS) (1097–1105).
Lee, J., and Nam, J. (2017). Multi-Level and Multi-Scale Feature Aggregation Using Pre-Trained CNN for Music Auto-Tagging. IEEE Signal Processing Letters, 24(8), 1208–1212. https://doi.org/10.1109/LSP.2017.2713830
Liu, B. (2012). Sentiment Analysis and Opinion Mining. Morgan and Claypool. https://doi.org/10.1007/978-3-031-02145-9
McFee, B., Raffel, C., Liang, D., Ellis, D. P. W., McVicar, M., Battenberg, E., and Nieto, O. (2015). Librosa: Audio and Music Signal Analysis in Python. In Proceedings of the Python in Science Conference (SciPy). https://doi.org/10.25080/Majora-7b98e3ed-003
Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv.
Oramas, S., Nieto, O., Barbieri, F., and Serra, X. (2017). Multi-Label Music Genre Classification from Audio, Text, and Images Using Deep Features. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR).
Picard, R. W. (1997). Affective Computing. MIT Press. https://doi.org/10.7551/mitpress/1140.001.0001
Russell, J. A. (1980). A Circumplex Model of Affect. Journal of Personality and Social Psychology, 39(6), 1161–1178. https://doi.org/10.1037/h0077714
Sarwar, B., Karypis, G., Konstan, J., and Riedl, J. (2001). Item-Based Collaborative Filtering Recommendation Algorithms. In Proceedings of the World Wide Web Conference (WWW) (285–295). https://doi.org/10.1145/371920.372071
Schedl, M. (2019). Deep Learning in Music Recommendation Systems. Frontiers in Applied Mathematics and Statistics, 5. https://doi.org/10.3389/fams.2019.00044
Scherer, K. R. (2005). What are Emotions? And how can they be Measured? Social Science Information, 44(4), 695–729. https://doi.org/10.1177/0539018405058216
Schuller, B., Batliner, A., Steidl, S., and Seppi, D. (2012). Recognising Realistic Emotions and Affect in Speech. IEEE Signal Processing Magazine, 29(4), 96–108.
Soleymani, M., Garcia, D., Jou, B., Schuller, B., Chang, S. F., and Pantic, M. (2017). A Survey of Multimodal Sentiment Analysis. Image and Vision Computing, 65, 3–14. https://doi.org/10.1016/j.imavis.2017.08.003
Tkalčič, M., De Carolis, B., de Gemmis, M., Odić, A., and Košir, A. (2019). Emotion-Aware Recommender Systems: A Review. Journal of Intelligent Information Systems, 53(1), 1–31.
Wang, X., He, X., Wang, M., Feng, F., and Chua, T. S. (2017). Neural Collaborative Filtering. In Proceedings of the World Wide Web Conference (WWW) (173–182). https://doi.org/10.1145/3038912.3052569
Yang, Z., Yang, D., Dyer, C., He, X., Smola, A., and Hovy, E. (2016). Hierarchical Attention Networks for Document Classification. In Proceedings of NAACL-HLT (1480–1489). https://doi.org/10.18653/v1/N16-1174
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© Granthaalayah 2014-2026. All Rights Reserved.