
HYBRID SCHEMES BASED ON WAVELET TRANSFORM AND CONVOLUTIONAL AUTO-ENCODER FOR IMAGE COMPRESSION
Houda Chakib 1![]()
![]() ,
Najlae Idrissi 1
,
Najlae Idrissi 1![]() , Oussama Jannani 1
, Oussama Jannani 1![]()
1 Data4Earth Laboratory, Faculty of Sciences and
Technics, Sulan Moulay Slimane University USMS, Morocco
|
|
|
ABSTRACT |
|
|
In recent years, image compression techniques have received a lot of attention from researchers as the number of images at hand keep growing. Digital Wavelet Transform is one of them that has been utilized in a wide range of applications and has shown its efficiency in image compression field. Moreover, used with other various approaches, this compression technique has proven its ability to compress images at high compression ratios while maintaining good visual image quality. Indeed, works presented in this paper deal with mixture between Deep Learning algorithms and Wavelets Transformation approach that we implement in different color spaces. In fact, we investigate RGB and Luminance/Chrominance YCbCr color spaces to develop three image compression models based on Convolutional Auto-Encoder (CAE). In order to evaluate the models’ performances, we used 24 raw images taken from Kodak database and applied the approaches on every one of them and compared achieved experimental results with those obtained using standard compression method. We draw this comparison in terms of performance parameters: Structural Similarity Index Metrix SSIM, Peak Signal to Noise Ratio PSNR and Mean Square Error MSE. Reached results indicates that with proposed schemes we gain significate improvement in distortion metrics over traditional image compression method especially SSIM parameter and we managed to reduce MSE values over than 50%. In addition, proposed schemes output images with high visual quality where details and textures are clear and distinguishable. |
|||
|
Received 19 February 2023 Accepted 20 March 2023 Published 05 April 2023 Corresponding Author Houda
Chakib, houda.chakib@yahoo.fr DOI 10.29121/IJOEST.v7.i2.2023.479 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2023 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: Wavelet Transform, RGB Color Space, YCbCr Color
Space, Convolutional Auto-Encoder, Image Compression |
|||
1. INTRODUCTION
The enormous increase of computer applications like Internet of Things IoT and the digitalization of human’s life sectors such medicine, multimedia… create a large number of data to handle. Consequently, image processing field especially compression part, has received significant interest from researchers in order to develop effective algorithms in purpose to achieve a simplified model using less memory than the original and compressed version visually indistinguishable from uncompressed one. This is the reason why it has been challenging for classic compression algorithms to adapt to the increasing demands and develop complete model compression pipeline that combines many approaches in the goal to take advantages and benefits from every one of them.
In this work, we are interested in one most popular deep learning algorithms called convolutional auto-encoder CAE. In fact, we develop three schemes for RGB image compression based on wavelet transform technique. Our main idea is to apply DWT algorithm to uncompressed RGB image in order to isolate approximate sub-band, containing relevant features, from unnecessary details sub-bands. After that, we get a copy version of original image by applying inverse wavelet transform process by omitting details sub-bands. Next step, output image feed a proposed CAE, that we configure and implement, to be reconstructed with less data by removing all irrelevant remained information. The second scheme investigate YCbCr color space. Indeed, approximate image reconstructed without original image details, is converted to luminance/chrominance space before feeding the CAE input by its luminance component. In this stage, we consider two directions: first one where we down sample chrominance coefficients by 2 and second one where we keep them without sampling. In both cases, we reconstruct new RGB image version by merging all components.
The aim of this combination is to develop efficient image compression systems that exploit advantages of each technique. In fact, in one hand, we have wavelets a strong tool recently emerged and supported by several research papers as a powerful mean to compress images with good visual quality and fewer bits. In the other hand, we have convolutional auto-encoder a neural network based on convolutional layers that captures recently, more and more significant attention of researchers. To achieve our work, we used database of Kodak that contains 24 uncompressed images commonly used to evaluate new image compression approaches by considering three known quality metrics: PSNR, MSE and SSIM. Our study investigate both color spaces: RGB and YCbCr.
The remainder of the paper is structured as follow: Section 2 gives an overview of the state of the art in this field. Section 3 shows working methodology including opted CAE architecture as well as steps followed to accomplish each approach. Section 4 covers the experimental processes carried out with all results achieved. Finally, to conclude this paper some conclusions and remaining challenges are drawn in Section 5.
2. STATE-OF-THE-ART
Digital image compression is a topical research area in image processing domain as it is employed in several applications such as aerial surveillance, recognition, medicine, multimedia… Moreover, every day the number of images handled keeps growing which requires more and more efficiency image compression methods that output images visually acceptable and occupied less storage space. In recent years and thanks to Machine Learning advances, different image compression techniques combining multi-resolution aspect of wavelets to parallel processing of data and training process of neuronal networks emerged for instance Zang and Beneveniste (1992), Osowski et al. (2006), Zhang (1997), Singh et al. (2012), Ahmadi et al. (2015). In fact, neural network implementation during each stage of an image compression process has received an important attention from scientists and many works have been developed during last years as in Krishnanaik et al. (2013), Denk et al. (1993), Dimililer and Khashman (2008), Alexandridis and Zapranis (2013). Furthermore, and since the rise of Deep Learning algorithms, networks based on deep layers have widely been involved in image compression process especially unsupervised auto-encoder that once combined to wavelets transform had led to promising results surpassing existing lossy image compression algorithms. In fact, in Chuxi et al. (2019) Y. Chuxi and al. propose a deep image compression approach in wavelet transform domain in which high frequency sub-band are predicted by low-frequency sub-band meanwhile all sub-bands feed different auto-encoders, which encode them with a conditional probability model for entropy coding. Moreover, their proposed model outputs results that outperform JPEG, JPEG2000, BPG, and some mainstream neural network-based image compression. In Ma et al. (2020), and al. propose an end-to-end image compression scheme combining wavelet transform with a trained auto-encoder that converts images into lossless coefficients quantized and encoded into bits. The experimental results achieved by their model, using Kodak dataset demonstrate that their approach leads to 17.34 percent bits saving over BPG. In Williams and Li (2018), T. Williams and R. Li. develop a scheme for image classification that converts data to wavelet domain, consequently important features learning occurred over differing low to high frequencies and by processing fused features mapping led to advance in detection and classification accuracy. In Paul et al. (2022), and al. propose a de-noising method composed by dual branch deep neural network-based architecture working on wavelet-transformed bands to remove multiple frequently encountered noise patterns from hyperspectral images. Experimental results demonstrate the superior performance aspect of the proposed network compared to other state-of-the-art de-noising methods. In Feng et al. (2022), and al. develop a model based on Haar wavelet transformation to use as feature extraction for data compression likewise, a pseudoinverse learning algorithm based auto-encoders to identify and recognize images. Experimental results show that proposed model, compared with filters, CNN, and pseudoinverse learning auto-encoders, takes less training time, at the same time it acquires comparative recognition accuracy. In Zhu et al. (2021), Q. Zho and al. propose a wavelet loss function to better generate and reconstruct images. In fact, wavelet transform is applied to reconstructed image loss function of the auto-encoder, and the frequency characteristics of the decomposed image are used to constrain it. By conducting their comparative experiments on two larger-size image datasets (FaceSrub, COIL20) and a small-size image dataset (Fashion_MNIST), the authors succeed to prove the effectiveness of their proposed loss function. At the same time, they propose a new image quality index called wavelet high-frequency signal-to-noise ratio (WHF-SNR), which can better measure quality of reconstructed image outputted by auto-encoder. Finally, in Luo et al. (2018) and al. present a new scheme to learn high-level representative features and conduct classification for hyperspectral image (HSI) data in an automatic fashion. Experimental results on two real HSI data sets demonstrate that proposed strategy improves classification performance in comparison with other state-of-the-art handcrafted feature extractors and their combinations.
To our knowledge, the current state-of-the-art of image compression methods based on mixture between wavelet transformations and convolutional auto-encoders had been investigated in RGB color space meanwhile; luminance and chrominance color space is still poor area that need to be explored. In this respect, we propose in this paper, image compression schemes that involve RGB color space as well as YCbCr space.
3. PROPOSED WORK AND METHODOLOGY
3.1. STEPS OF PAPER TOPIC
The particularity
of the work presented in this paper is two folded. Firstly, we propose a RGB
image compression scheme that combines multi-resolution representation of
wavelet transform with nonlinear dimensionality reduction aspect of
convolutional auto-encoder. Secondly, we investigate YCbCr space to develop a
new model that involves auto-encoder algorithm for image reconstruction both with
sampled and unsampled chrominance. Thus, in this paper we present three lossy
image compression schemes suitable for high dimensional data. The whole
research idea is depicted by Figure 1.
Figure 1
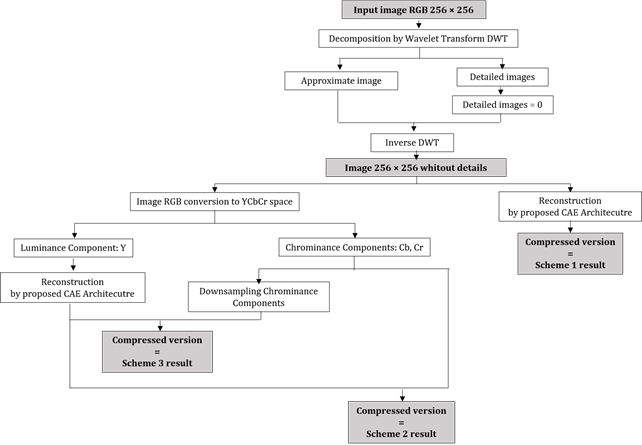
|
Figure 1 Flowchart of Paper Idea |
According to this
flowchart, to accomplish our work we follow the following steps:
1)
A set of
24 RGB images have been downsized to 256 × 256 for research purpose. Figure 2 summarizes Kodak database used for this study.
Figure 2

|
Figure 2 Kodak Database Used |
2)
Digital wavelets
transform DWT is applied to RGB image consequently four sub-bands emerged: one
approximate low-pass sub-image and three detailed sub-images.
3)
We
reconstruct again the 256×256 original image without its details sub-bands
using inverse digital transform IDWT as illustrated by Figure 3.
Figure 3
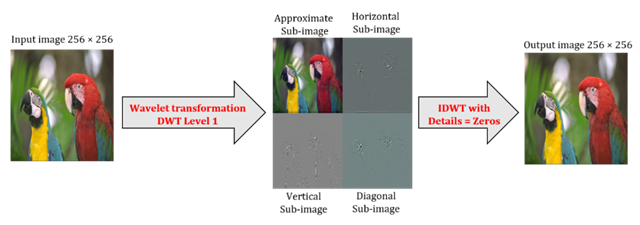
|
Figure 3 Image Reconstruction By IDWT |
4) In this stage, our study takes two parallel directions:
· First direction is carried out in RGB space. In fact, color image feed our proposed CAE input to get a compressed version of it in output.
· Second direction: RGB image is decomposed in YCbCr color space and luminance component Y passes through CAE layers to be compressed. In this case, we propose two schemes one with chrominance components downsampled by 2 and the other without sampling those components.
3.2. PROPOSED AUTOENCODER ARCHITECTURE
As aforementioned, we propose hybrid schemes for color image compression combining multi approaches. Indeed, Deep learning auto-encoder algorithm plays a key role in this work. We opt for this type of machine learning architecture because they are able to reconstruct images just by learning relevant features concentrated in its space latent. As it is well known, a CAE with deeper architecture is enriched over by higher features, we propose in our study a configuration composed with 5 convolutional blocks as encoder part and the same number of blocks as decoder part. Thus, encoder part consists of convolutional blocks with following components:
1) 1st convolutional block corresponds to two successive convolutional layers. The first one calculates a convolution product between input data and 64 filters of 3×3 to output 64 features maps activated by ReLU activation function (Rectified Linear Unit) defined as Farnoush (2017), Nwankpa et al. (2018):
![]() Equation
1
Equation
1
The second layer performs Max-pooling operation that divides the input to pooling regions and computes the maximum value of each region. All these operations are carried out with stride parameter set to 2.
2) 2nd, 3rd, 4th and 5th convolutional blocks have the same architecture as the previous one with the difference that the number of filters is increased to 128, 256, 512, 1024 respectively. The last convolutional block generates auto-encoder latent features representation, which preserves only the most relevant aspects of input image.
The opposite side of the CAE called decoder has also five convolutional blocks aiming to reproduce input image from latent space. The layers have the following characteristics:
1) 1st to 5th convolutional blocks in which, each block contains transpose convolutional layer, with same number of filters and kernels as the encoder blocks in order to upsample data by 2. Convolutional layer using ReLU activation function follows each block.
2) An extra convolutional layer is added at the end of the CAE architecture adopted for this work. Its purpose is to output a compressed version of image in network’s input. This last layer contains one filter of size 3×3 and a stride of 1 with sigmoid activation function defined as Farnoush (2017) Nwankpa et al. (2018):
![]() Equation
2
Equation
2
3.3. BASELINE METHOD
Baseline compression algorithm based on wavelet transformation is accomplished as follow:
· First, RGB image is decomposed in level 1 using a chosen wavelet mother.
· Second, quantization technique is applied to the spectral coefficients.
· Finally, Huffman code is used to get binary code of data. Coded image is than transmitted through transmission channel. In receptor side, binary data is decoded, and inverse quantization is applied followed by inverse wavelet transform in purpose to get compressed copy of original image.
4. EXPERIMENT PROCESS
Experiment process begins with preparing the set of images concerned by our work. In fact, we resize all Kodak images to 256 × 256 and decompose them by wavelet transform in level1 using Bior4.4 wavelet mother. Next, we reconstruct image using inverse wavelet transform and omitting details coefficients. This obtained image is the core of all proposed schemes. For experimental purpose, Python 3.10 platform was considered and executed in Pycharm EDI with some basic packages taken like Numpy, Pywt, Matplotlib and others. It is worth adding that data analysis packages like Keras, Skimage and Tensorflow was employed in an i7 core processor with 2.8 GHz speed and 16 Go RAM.
4.4. 1ST PROPOSED SCHEME
The first image compression scheme investigate RGB space.
According to our hypothesis, IDWT output image feed CAE input layer to be
reconstructed in output. The proposed auto-encoder is trained during 2000 epochs 2s each one, which allows
us to achieve loss error value close
to![]() and
accuracy rate between 97% and 99%. In addition, we use Adam optimizer as
network optimizer Kingma and Ba (2017) and Batch normalization algorithm to normalize our data Ioffe and Szegedy (2015). Figure 4 clearly explains this
scheme.
and
accuracy rate between 97% and 99%. In addition, we use Adam optimizer as
network optimizer Kingma and Ba (2017) and Batch normalization algorithm to normalize our data Ioffe and Szegedy (2015). Figure 4 clearly explains this
scheme.
Figure 4
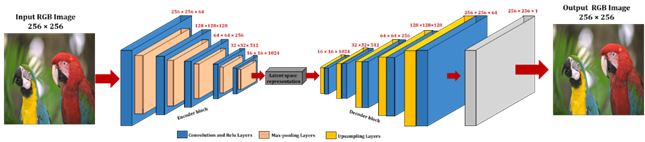
|
Figure 4 Proposed CAE Architecture and Experiment Steps for Scheme 1 |
4.2. 2ND PROPOSED SCHEME
The second image compression scheme investigate YCbCr
domain. Thus, RGB image is transformed to luminance and chrominance space to
separate luminance component. This latter feed our proposed CAE input to be
reconstructed with less data. Training
continues about 2000 epochs where each one takes 2s. All images are
reconstructed with accuracy around 99,8% and loss error close to ![]() . The auto-encoder CAE outputs luminance image
that we merge with unsampled chrominance components in the purpose to obtain
colored image. Figure 5 illustrates second
scheme process.
. The auto-encoder CAE outputs luminance image
that we merge with unsampled chrominance components in the purpose to obtain
colored image. Figure 5 illustrates second
scheme process.
Figure 5
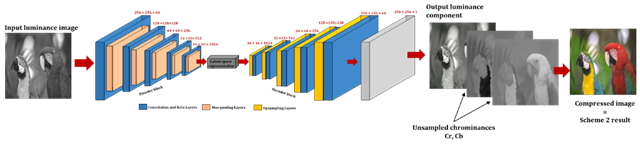
|
Figure 5 Experiment Steps for Proposed Scheme 2 |
4.3. 3RD PROPOSED SCHEME
This scheme is a
part of the last one the only difference is that in this case; we down-sample
chrominance components by 2. We add this case to figure out sampling effect in
reconstructed image. Proposed method is depicted in Figure 6.
Figure 6

|
Figure 6 Experiment Steps for Proposed Scheme 3 |
To evaluate compression
models performance, we consider the following quality metrics:
·
MSE
(Mean Square Error) compute mean square error value between uncompressed image
I pixels and those within compressed image J and it is defined by following
equation Rabbani and Jones (1991), Antonini et al. (1992) :
![]() Equation 3
Equation 3
C: number of channels
M×N: size of each
image.
·
SSIM (Structural
Similarity Index Metric) measures similarities within pixels of two images and
defined as Wang et al. (2004), Wang et al. (2004) Rozema
et al. (2022).
![]() Equation 4
Equation 4
With:
x and y two images
of common size N×N;
![]() : pixel sample mean of x;
: pixel sample mean of x;
![]() : pixel sample mean of y;
: pixel sample mean of y;
![]() :
variance of x;
:
variance of x;
![]() :
variance of y;
:
variance of y;
![]() :
covariance of x and y;
:
covariance of x and y;
![]() ;
;
L : dynamic range
of the pixel-values;
k_1=0.01 and
k_2=0.03.
Some particular
cases: SSIM is equal to -1 means the two images have opposite contrast, equal
to 0 means the two images are completely different and finally, equal to 1
means the two images are completely identical Antonini et al. (1992), Rozema
et al. (2022).
·
PSNR
(Peak Signal to Noise Ratio) measures distortion that appears in images and
videos after lossy compression. It is expressed in decibels and defined as Huynh-Thu and Ghanbari (2012):
![]() Equation
5
Equation
5
With MAX is
maximum valid value for a pixel.
5. RESULTS AND DISCUSSIONS
In this article, we proposed three compression schemes that we validated thanks to experimental results that we carried out on Kodak images database. To evaluate our proposed approaches performance, we considered following quality metrics: MSE, PSNR and SSIM that we computed, in one side between original image and its copy reconstructed by proposed schemes and in the other side between original image and its compressed version obtained by application of baseline method. Finally, we compared the two values of each parameter and summarized the comparison results in Figure 7.
Figure 7
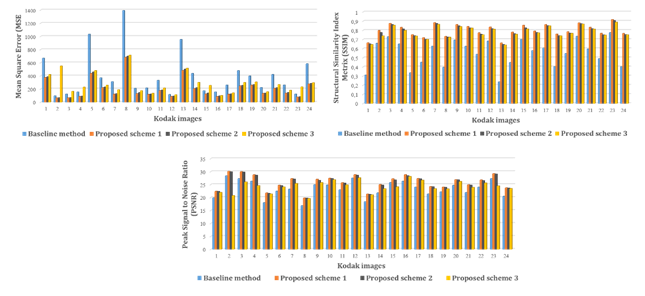
|
Figure 7 Experiment Results in Terms of MSE, SSIM and PSNR Quality Metrics |
According to this representation, all quality metrics values obtained using proposed approach 1 and 2 are greater than those achieved by baseline method in blue color. To clarify more, let take a sight at each one:
· First curve shows MSE parameter vs 24 Kodak images for the four approaches, we can see clearly that this parameter is widely decreased and can reach in some cases more than 50% of reduction in case of scheme 1 and 2. In contrast, results obtained using scheme 3 aren’t very conclusive as in some cases, they overcome baseline results which is unfortunately bad thing. Consequently, we can presume that these bad results are due to sampling chrominance components.
· Second curve indicates SSIM (structural similarity index) parameter vs 24 Kodak images. Recently, this parameter is widely used to calculates similarities between images as it is based on perception model that exploits tight inter-dependencies between pixels Wang et al. (2004), Wang et al. (2004). According to SSIM values shown by curve 2 in Figure 7, we can confirm that the measurements achieved by all proposed methods exceed greatly values obtained by standard image compression technique. In addition, we can notice that first proposed model over performs others schemes which prove that this compression scheme yield high-visual quality of compressed image. Furthermore, in some cases, this parameter is improved by 3
· Lastly, the third curve shows PSNR values achieved by each proposed model in our study. Despite the fact that this coefficient has been shown to perform poorly when it comes to evaluate images quality after a lossy compression Huynh et al. (2008), Huynh-Thu and Ghanbari (2012). In these experiments, evaluation by this parameter is very conclusive as we obtain compressed images visually undistinguishable from original version. Furthermore, there is an improvement of this quality metric in case of scheme 1 and 2.
In the following, we present in Table 1 some best metrics values issue from the work presented in this article as well as depict in Figure 8 some best results in terms of images.
Table 1
|
Table 1 Some Best Quality Metrics Results Issue from This Work |
||||||||||||
|
|
MSE |
SSIM |
PSNR |
|||||||||
|
Images |
Baseline method |
1st scheme |
2nd scheme |
3rd scheme |
Baseline method |
1st scheme |
2nd scheme |
3rd scheme |
Baseline method |
1st scheme |
2nd scheme |
3rd scheme |
|
Kod03 |
122.432 |
65.877 |
68.756 |
163.581 |
0.729 |
0.875 |
0.862 |
0.854 |
27.252 |
29.943 |
29.759 |
25.993 |
|
Kod07 |
311.306 |
122.398 |
128.02 |
187.855 |
0.627 |
0.883 |
0.872 |
0.864 |
23.199 |
27.253 |
27.058 |
25.393 |
|
Kod09 |
210.131 |
129.268 |
143.745 |
174.205 |
0.693 |
0.862 |
0.846 |
0.839 |
24.906 |
27.016 |
26.555 |
25.72 |
|
Kod10 |
215.758 |
118.263 |
122.595 |
134.315 |
0.625 |
0.841 |
0.825 |
0.823 |
24.791 |
27.402 |
27.246 |
26.85 |
|
Kod15 |
172.818 |
124.098 |
138.806 |
253.71 |
0.7 |
0.854 |
0.826 |
0.813 |
25.755 |
27.193 |
26.707 |
24.087 |
|
Kod17 |
259.424 |
121.317 |
125.157 |
140.267 |
0.605 |
0.862 |
0.848 |
0.846 |
23.991 |
27.292 |
27.156 |
26.661 |
|
Kod20 |
221.571 |
133.569 |
137.774 |
157.944 |
0.734 |
0.88 |
0.87 |
0.868 |
24.676 |
26.874 |
26.739 |
26.146 |
|
Kod23 |
122.423 |
78.812 |
81.826 |
232.203 |
0.775 |
0.917 |
0.906 |
0.888 |
27.252 |
29.165 |
29.002 |
24.472 |
Figure 8

|
Figure 8 Some Experimental Results in Terms of Images |
Based on experimental results depicted in Figure 7 and Figure 8, we can confirm that we can achieve best quality metrics just by applying wavelet transform in level one and with a specific auto-encoder architecture. Likewise, we can get images satisfactory in appearance regardless of the color space used. However, sampling chrominance components reduces the amount of information and leads to slight change in image color, which is the case with the third scheme.
6. CONCLUSIONS AND FUTURE WORKS
In this paper, we proposed three new schemes for image compression as hybrid form combining two techniques widely used in image processing field: digital wavelet transform DWT and unsupervised convolutional auto-encoder. We aimed by this study to demonstrate that it is not necessary to go through the standard compression techniques to compress an image. Indeed, the proposed schemes follow a common pattern based on the use of wavelet transform to eliminate redundant details reinforced by an unsupervised convolutional neural network auto-encoder. We investigated both RGB and YCbCr color spaces and proposed three schemes for image compression. Experimental results show that proposed schemes 1 and 2 outperforms traditional image compression technique especially in terms of similarity, as we can’t separate visually compressed version of images from uncompressed ones. Likewise, we achieved significant improvement of all quality metrics. Unlikely, proposed scheme 3 present defaults concerning image visual side in spite of the fact that it performs baseline technique in terms of all performance metrics.
As future works, our goal will be to focus on compression ratio by applying DWT in high level and implement deeper CAE in order to develop image compression models that outperform traditional compression approaches based on wavelet transformation such as JPEG2000. Moreover, we will take into account running time as additional parameter in our study.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Ahmadi, K., Javaid, A. Y., and Salari, E. (2015). An
Efficient Compression Scheme Based on Adaptive Thresholding In Wavelet Domain
Using Particle Swarm Optimization. Signal Processing: Image Communication, 32,
33-39. https://doi.org/10.1016/j.image.2015.01.001.
Alexandridis, A. K., and Zapranis, A. D. (2013).
Wavelet Neural Networks : A Practical Guide. Neural Networks, 42, 1-27. https://doi.org/10.1016/j.neunet.2013.01.008.
Antonini,
M., Barlaud, M., Mathieu, P., and Daubechies, I., ″ IEEE. (1992).
Image Coding Using Wavelet Transform. IEEE Transactions on Image Processing,
1(2), 205-220.
https://doi.org/10.1109/83.136597.
Chuxi, Y., Zhao, Y., and Wang, S., (2019). Deep Image
Compression in the Wavelet Transform Domain Based on High Frequency Sub-Band
Prediction,″ IEEE Computer Science. https://doi.org/10.1109/ACCESS.2019.2911403.
Denk, T., Parhi, K. K., and Cherkassky, V. (1993). Combining
Neural Network and the Wavelet Transform for Image Compression Proceeding of
International Conference, (1), 637-640. https://doi.org/10.1109/ICASSP.1993.319199.
Dimililer, K., and Khashman, A. (2008). Image Compression Using Neural Networks and Haar Wavelet. Transaction on Signal Processing, ISSN, 4, 2008. https://dl.acm.org/doi/10.5555/1466835.1466844.
Farnoush, F., (2017). ‶ Learning Activation Functions in Deep Neural Networks, ʺ Ecole Polytechnique, Montreal (Canada) ProQuest dissertations publishing, 10957109.
Feng, Q., Yin, Q., and Guo, P., (2022). Image Recognition with Haar Wavelet and Pseudoinverse Learning Algorithm Based Autoencoders,″ Journal of Physics: Conference Series, 2278. https://doi.org/10.1088/1742-6596/2278/1/012019.
Huynh-Thu,
Q., and Ghanbari, M. (2008). Scope of Validity of PSNR in Image/Video
Quality Assessment. Electronics Letters, 44(13), 800. https://doi.org/10.1049/el:20080522.
Huynh-Thu, Q., and Ghanbari, M. (2012). The Accuracy of PSNR in
Predicting Video Quality for Different Video Scenes and Frame Rates.
Telecommunication Systems. Janv 2012, 49(1), 35-48. https://doi.org/10.1007/s11235-010-9351-x.
Ioffe, S., and Szegedy, C., (2015). ‶ Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift,ʺ Machine Learning, Arxiv:1502.03167[Cs.LG]. (2015). https://doi.org/10.48550/arXiv.1502.03167.
Kingma, P. D., and Ba, J. L., (2017). ADAM : A Method for Stochastic Optimization, ″ ArXiv:1412.6980v9 [Cs.LG].
Krishnanaik, V., Someswar, G. M., Purushotham, K., and Rajaiah, A. (2013). Implementation of Wavelet Transform, DPCM and Neural Network for Image Compression. International Journal of Engineering and Computer Science ISSN : 2319-7242, 2(8), 2468-2475.
Luo, H., Tang, Y. Y., Biuk-Aghai, R. P., Yang, X., Yang, L., and Wang,
Y.,(2018). ‶Wavelet-Based
Extended Morphological Profile and Deep AutoEncoder for Hyperspectral Image
Classification, ʺ International Journal of Wavelets. (2018).
Multiresolution and information processing, 16(03), 1850016. https://doi.org/10.1142/S0219691318500169.
Ma, H., Liu, D., Yan, N., Li, H., and Wu, F., (2020). ‶End-To-End Optimized Versatile Image Compression with Wavelet-Like Transform, ʺ IEEE Transactions on Pattern Analysis and Machine Intelligence, 44 (3). https://doi.org/10.1109/TPAMI.2020.3026003.
Nwankpa, C. E., Ijomah, W., Gachagan, A., and Marshall, S. (2018). Activation Functions: Comparison of Trends in Practice and Research for Deep Learning ″, Arxiv:1811.03378v1 [Cs.LG]. Activation Functions : Comparison of Trends in Practice and Research for Deep Learning ″.
Osowski, S., Waszczuk, R., and
Bojarczak, P., (2006). Image Compression Using Feed
Forward Neural Networks- Hierarchical Approach, ″ Lecture Notes in
Computer Science. Book Chapter, Springer - Verlag, 3497, 1009-1015. https://doi.org/10.1007/3-540-59497-3_280.
Paul, A., Kundu, A., Chaki, N., Jha, C. S., and Dutta, D., (2022).
‶ Wavelet
Enabled Convolutional AutoEncoder Based Deep Neural Network for Hyperspectral
Image Denoising,ʺ
Multimed Tools Appl 81, 2529-2555. https://doi.org/10.1007/s11042-021-11689-z.
Rabbani, M. and Jones, P.W. (1991). ‶ Digital Image Compression Techniques, ʺvol.TT07, SPIE Press Book, Bellingham, Washington, USA.
Rozema, R., Kruitbosch, H. T., Van Minnen, B., Dorgelo, B., Kraeima, J., and Van Ooijen, P. M. A., (2022). ‶Structural Similarity Analysis of Midfacial Fractures-A Feasibility Study, ʺ Quant Imaging Med Surg., 12(2), 1571-1578. https://doi.org/10.21037/qims-21-564.
Singh,
A. V., and Murthy, K. S. (2012). Neuro-Wavelet Based Efficient Image
Compression Using Vector Quantization. International Journal of Computers and
Applications (0975-08887), 49-N°.3. https://doi.org/10.5120/7610-0653.
Wang,
Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P., (2004). Image
Quality Assessment: from Error Visibility to Structural Similarity. IEEE
Transactions on Image Processing, 13(4), 600-612. https://doi.org/10.1109/tip.2003.819861.
Wang, Z., Simoncelli, E. P., and Bovik, A. C., (2004). Multiscale Structural Similarity for Image Quality Assessment,″ Conference Record of the Thirty-Seventh Asilomar Conference on Signals, Systems and computers, 2, 1398-1402. https://doi.org/10.1109/ACSSC.2003.1292216.
Williams, T., and Li, R., (2018). An Ensemble of Convolutional Neural Networks Using Wavelets for Image Classification, ″ Journal of Software Engineering and Applications, 11(02). https://doi.org/10.4236/jsea.2018.112004.
Zang,
Q., and Beneveniste, A., (1992).‶Wavelet
Networks, ʺ IEEE Tans.
Neural Networks, 7(1), 889-898. https://doi.org/10.1109/72.165591.
Zhang,
Q. (1997). Using Wavelet Network in Nonparametric Estimation. IEEE
Transactions on Neural Networks, 8(2), 227-236. https://doi.org/10.1109/72.557660.
Zhu, Q., Wang, H., and Zhang, R. (2021). Wavelet Loss Function for Auto-Encoder. In IEEE Access, 9, 27101-27108. https://doi.org/10.1109/ACCESS.2021.3058604.
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© Granthaalayah 2014-2023. All Rights Reserved.

