
Criminality data scrutiny using logistic regression algorithm
Dr. G. Soma Sekhar 1![]() , Puvvada Abhinaya 2,
Rachapudi Jayani 2, Dr. D.
Srinivasa Rao 3
, Puvvada Abhinaya 2,
Rachapudi Jayani 2, Dr. D.
Srinivasa Rao 3
1 Associate
Professor, Department of CSE, Geethanjali College of Engineering and Technology,
Hyderabad, India
2 Department
of CSE, Geethanjali College of Engineering and Technology, Hyderabad, India
3 Assistant Professor, Department of CSE, GITAM Deemed to be
University, Hyderabad, India
|
|
|
ABSTRACT |
|
|
The quantity
of criminal cases in India is rising rapidly, which is the reason there are
likewise a rising number of cases as yet extraordinary. Criminal cases are
expanding ceaselessly, making it difficult to sort and determine them. It's
essential to perceive an area's patterns of crime to prevent it from working
out. On the off chance that the specialists entrusted with researching
violations have a strong comprehension of the patterns in crime happening in
a specific area, they will actually want to improve. Finding the examples of
crime in a particular area should be possible by applying AI and different
calculations. This review predicts the sorts of wrongdoings that will happen
in a given area utilizing wrongdoing information, which facilitates the characterization
of criminal cases and considers suitable activity. This exploration utilizes
information from the most recent 18 years that were assembled from various
solid sources. This article utilized choice, erasing invalid qualities, and
mark encoding to clean and support the information since information
pre-handling is similarly just about as vital as definite expectation. A
compelling AI model for estimating the resulting criminal case is given by
this exploration. |
|||
|
Received 24 May 2023 Accepted 25 June 2023 Published 10 July 2023 Corresponding Author Dr. G.
Soma Sekhar, gsomasekharonline@gmail.com DOI 10.29121/granthaalayah.v11.i6.2023.5182000 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2023 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: Data Scrutiny, Criminal Cases, AI Model |
|||
1. INTRODUCTION
As additional crimes are being carried out, there are as of now more crook cases forthcoming in India than at any time in recent memory. A total interior examination and examination ought to be led to determine a case in light of explicit information. Given the volume of wrongdoing information now accessible in India, it is excessively extreme for the authorities to break down and settle on these lawbreaker cases. This study recognizes this as a critical issue and spotlights thinking of an answer for how violations are chosen to be committed. The logical field of AI manages PC decision-production without human inclusion. Mechanized or self-driving vehicles are contemporary instances of how AI is being utilized in many fields. We can figure explicit results in light of our bits of feedback and propose an answer for tackling wrongdoing cases in India by utilizing AI calculations. Grouping and relapse are the two most utilized classes of expectation calculations. This area of wrongdoing information forecast utilizes grouping. Order is a directed expectation technique that has been applied in different fields, like stock estimating and the drug business. This paper's significant objective is to look at a couple of calculations that might be utilized to gauge and examine wrongdoing information and to expand the accuracy of such models through information handling to come by improved results. The objective is to approve the preparation dataset with the test dataset to foster the fundamental model to anticipate the information. Here, choice trees, irregular backwoods, and strategic relapse displaying are being utilized for order.
2. Logistic regression algorithm
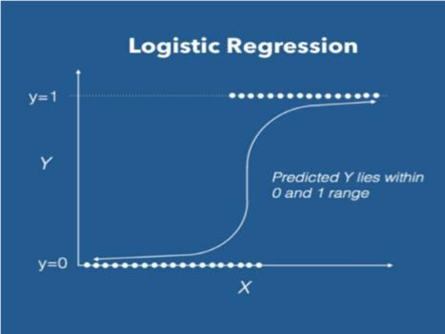
Logistic regression is a statistical approach employed in the development of machine learning models, wherein the dependent variable takes on a dichotomous form, meaning it assumes binary values. Logistic regression is a statistical method employed to elucidate the data and the linkage relationship between the response variable and at least one predictor variable. The independent variables in a research study may represent nominal, ordinal, or interval data. The term "logistic regression" derives from the utilization of the logistic function. The sigmoid function, commonly referred to as the logistic function, is utilized in mathematical modeling and analysis. The logistic function exhibits a range of values that lies within the interval of 0 and 1.
3. RELATED WORK
McClendon, Lawrence, and Natarajan McClendon & Meghanathan (2015) proposed an undertaking "Utilizing AI calculations to examine wrongdoing information." which manages the information mining and AI methods to recognize wrongdoing and forestall it. Their exploration was utilized to feature WEKA, a non-proprietary information mining programming, to direct a similar report amongst vicious wrongdoing designs from the Networks and Wrongdoing Unnormalized Dataset given by the College of California-Irvine storehouse and genuine wrongdoing factual information in order to achieve province of Mississippi that has been given by neighborhoodscout.com. They carried out Straight Relapse, added substance Relapse, and Choice Stump calculations utilizing a similar limited set of elements, on the Networks and Wrongdoing Dataset. In general, the direct relapse calculation played out the best among the three chosen calculations. The extent of their undertaking is to demonstrate the way that compelling and exact AI calculations can point towards information.
Bharati & Sarvanaguru (2018) proposed an examination of “Crime Prediction and Analysis Using Machine Learning” in the International Research Journal of Engineering and Technology (IRJET). Their venture is spurred by the way that India has seen an ascent in criminal cases because of which the quantity of cases forthcoming is likewise stacking up. It is essential to first comprehend the wrongdoing design to keep it from happening. This paper utilizes a wrongdoing informational index and forecasts the sorts of violations in a specific region which helps in setting up the grouping of criminal cases. The informational index utilized is gathered for a long time from confided-in sources. This paper features the utilization of element choice, eliminating invalid qualities and name encoding to clean the information. The principal point of this paper is to consider a few calculations to foresee and examine the wrongdoing information and furthermore work on the exactness of those models by information handling to get improved results. The machine learning models used here for prediction are Logistic Regression, Decision Tree Classification and Random Forest Classification.
Wang et al. (2013) presented their exploration of "Learning to detect patterns of Crime." at the Joint European Gathering on AI and information revelation in Data sets. Springer, Berlin, Heidelberg. They present a novel, vigorous information-driven regularization methodology called Adaptive Regularized Boosting (AR-Lift), persuaded by a craving to decrease over-expungement of data. They supplant AdaBoost's complex system with a standardized delicate edge that compromises between a bigger edge, to the detriment of misclassified errors. Limiting this regularized remarkable misfortune brings about a helping calculation that loosens up the frail learning supposition further: it can utilize classifiers with mistakes more prominent. This empowers a characteristic expansion to multiclass aiding and further decreases overfitting in both double and multiclass cases. They infer limits for preparing and speculation mistakes and relate them to AdaBoost. At last, they show observational outcomes and crucial information that lay out the power of our methodology and further developed execution generally.
Sathyadevan et al. (2014) presented their exploration of “Crime analysis and prediction using data mining” at the First International Conference on Networks & Soft Computing (ICNSC 2014) 2014 Aug 19 (pp. 406-412) IEEE. Wrongdoing examination and counteraction is a deliberate methodology for recognizing and analyzing fraud examples and patterns. This architecture can foresee locales that have a high probability of wrongdoing events and can imagine crisis regions. The rising appearance of mechanized frameworks, wrongdoing information experts can help Policemen to accelerate the most common way of tackling violations. The idea of information mining allows us to separate ambiguous and useful data from unstructured information. Here, software engineering and law enforcement foster an information gathering technique that can assist with settling violations quicker. Rather than zeroing in on reasons for wrongdoing events like the crook foundation of the criminal, political hostility, and are zeroing in for the most part on wrongdoing elements every day.
4. PROPOSED FRAME WORK
The review work, which was finished by glancing through many such records, filled in as the establishment for the proposed framework. The area and the kinds of wrongdoing that are going on there are utilized to gauge practically all violations. Straight Relapse, Choice Tree, and Irregular Woodland models are utilized in this paper to foresee wrongdoings since research in the past has shown that they will often have great exactness. This study uses the from data.world.com dataset. As per the state and year, the informational index incorporates different wrongdoing sorts that are executed in India. This exposition involves a few wrongdoing sorts as its feedback and results in the geographic district where every wrongdoing is perpetrated. Information cleaning, highlight determination, eliminating invalid qualities, and information scaling through normalizing and normalizing are all essential for the information pre-handling process. During information planning, the information is liberated from invalid qualities that could decisively impact the model's precision, and component determination is utilized to pick just the fundamental attributes that won't influence the model's exactness. The picked models, for example, Strategic Relapse, Choice Tree, and Irregular Backwoods, are prepared by partitioning the information into train and test many figures pre-handling. We use grouping models for this situation since the result that is required is an all-out esteem. The information forecast is finished utilizing the Python language.
5. Implementation and Result Analysis


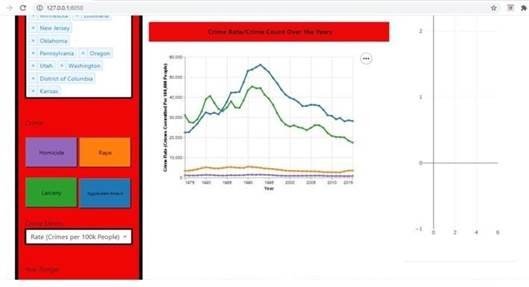
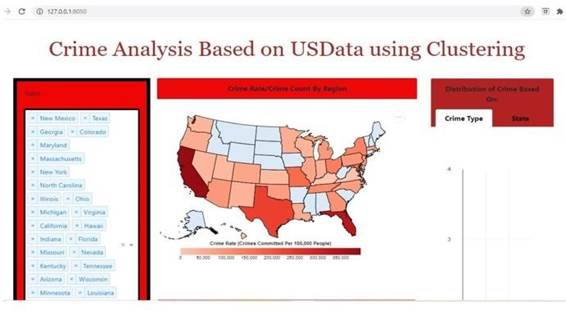
|
Test case Id |
Test case Name |
Test case description |
Test Steps |
Test Case Status |
Test Priority |
||
|
Step |
Expected |
Actual |
|||||
|
1 |
Start the Application |
Host the application and
test if it starts making sure the required software is available |
If it does not start |
We cannot run the
application |
The application hosts
success |
High |
High |
|
2 |
Home page |
Check the deployment
environment for properly loading the application |
If it does not load |
We cannot access the
application |
The application is running
successfully |
High |
High |
|
3 |
User Mode |
Verify the working of the
application in freestyle mode |
If it does not respond |
We cannot use the freestyle
mode |
The application displays the
freestyle page |
High |
High |
|
4 |
Data Input |
Verify if the application
takes input and updates |
If it fails to take the
input or store in the database |
We cannot proceed further |
The application updates the
input to application |
High |
High |
6. Conclusion
Essential data on criminal conduct in an area clearly has markers that AI specialists will use to classify a crime given an area and date. The dataset's unequal classes cause issues for the preparation specialist, yet it was inclined to fix the issue by finishing and under-inspecting the dataset. This paper confers a wrongdoing information expectation involving a Colab journal with Python as its center language. Python gives work in libraries like Pandas and NumPy along which the effort will be finished all the more rapidly, and Scikit gives every one of the cycles of how to utilize various libraries given by python. The exactness of the Arbitrary Woods not entirely set in stone to be great with a precision of 95.122%. Expectation results shift for various calculations.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Bharati, A., & Sarvanaguru, R. A. K. (2018). Crime Prediction Andanalysis Using Machine Learning. In International Research Journal of Engineering and Technology (IRJET), 05(09), 1037-1042.
Chen, H., Chung, W., Xu, J. J., Wang, G., Qin, Y., and Chau, M. (2004). Crime Data Mining : A General Framework and Some Examples. Computer, 37(4), 50-56. https://doi.org/10.1109/MC.2004.1297301.
McClendon, L., & Meghanathan, N. (2015). Using Machine Learning Algorithms to Analyze Crime Data. Machine Learning and Applications, 2(1), 1-12. https://doi.org/10.5121/mlaij.2015.2101.
Nath, S. V. (2006). Crime Pattern Detection Using Data Mining. In. 2006 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology Workshops, 41-44. https://doi.org/10.1109/WI-IATW.2006.55.
Sathyadevan, S., Devan, M. S., & Gangadharan, S. S. (2014). Crime Analysis and Prediction Using Data Mining First International Conference on Networks Y Soft Computing (ICNSC2014). IEEE Publications, 406-412. https://doi.org/10.1109/CNSC.2014.6906719.
Wang, T., Rudin, C., Wagner, D., & Sevieri, R. (2013). Learning to Detect Patterns of Crime. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 515-530. https://doi.org/10.1007/978-3-642-40994-3_33.
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© Granthaalayah 2014-2023. All Rights Reserved.

