ShodhKosh: Journal of Visual and Performing ArtsISSN (Online): 2582-7472
|
|
Embodied Intelligence and Algorithmic Expression: Rethinking Dance in the Age of AI
Liang Zhang 1![]()
![]()
1 Department
of Dance, General Graduate School, Sejong University, Seoul, 05006, South Korea
|
|
|
ABSTRACT |
|
|
Dance is
increasingly becoming an artificial intelligence dependent technical space of
generation, correction, improvisation, preservation of culture, co-performance. But most evaluations of AI-dance systems
still focus on motion realism, beat correspondence or benchmark precision,
but not on as much embodiment, expressive agency or agency sharing between
dancer and algorithm. This paper is a unique multiple-case
technical research of fifteen published AI-dance systems, published
between 2021 and 2026. The study constructs an analytic case corpus and makes
comparisons between systems in terms of a common coding matrix, which records
technical objective, input modality, output form, interaction mode, locus of
control, evaluation regime and four layers of embodied intelligence:
kinematic, semantic, relational and cultural, rather than the field being a
review problem. The results show that the current systems are very advanced
in terms of kinematic intelligence and are increasingly becoming capable of
giving semantic guidance with the aid of text, style labels and
language-model prompting. Yet, relational reciprocity and cultural grounding
is much less common. Co-performance systems that are live have the highest
scores of embodied intelligence, with offline
generators at the level of motion fidelity. Based on these findings, the
article proposes a technical form of expression of algorithms that is
designed on the premise of five design specifications: bodily alignment,
semantic articulation, reciprocal responsiveness, contextual grounding, and
reflexive human control. The article argues that the future of AI-dance
studies should not be viewed in terms of its capacity to produce plausible
movement but in terms of how it is able to sustain embodied agency, interpretive
openness, and culturally situated expression. |
|||
|
Received 17 February 2026 Accepted 22 March 2026 Published 16 April 2026 Corresponding Author Liang
Zhang, 1014918275@qq.com DOI 10.29121/shodhkosh.v7.i1.2026.7603 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2026 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: Embodied Intelligence, Algorithmic Expression,
Human-AI Choreography, Dance Computing, Co-Creative Performance |
|||


1. INTRODUCTION
Dance has gone into a new period of computation. Within a very brief time frame, artificial intelligence has progressed not only to much more general tasks, like creating 3D choreography based on music, or changing the style of motion between performers, or correcting amateur dancers, or simulating a duet, or facilitating access to cultural dance libraries, but also to systems capable of creating 3D choreography, based on music, and altering movement style, across performers, and correct This has grown the technical field due to the coincidence of various enabling conditions: larger multimodal data, more powerful sequence models, diffusion and masked-motion architectures, higher-quality motion capture, and the seamless incorporation of language interfaces into generative systems. It is not merely that AI is now able to do more with dance. Instead, dance has been used as a place where various models of intelligence are being coded, experimented and aestheticized using the moving body.
The most famous addition to the recent work is the AI Choreographer, which trained the AIST++ corpus with a full-attention cross-modal transformer to produce 3D dance motion conditioned on music Li et al. (2021). That contribution set a standard of quality of motion and alignment of music, and also showed the usefulness of large-scale paired dance-music data. Soon after, the field broadened in several directions: from solo to group choreography through AIOZ-GDANCE and music-driven group generation Le et al. (2023); from synthesis to enhancement in systems such as Let’s All Dance Zhou et al. (2023); from generic motion to stylistic transformation in multimodal dance style transfer Yin et al. (2023), from laboratory generation to cultural and archival mediation in DanXe and related heritage platforms Stacchio et al. (2024), Garzarella et al. (2024); and from offline prediction to live collaboration in Human-AI Co-Dancing, LuminAI-centred studies, and real-time interaction work Pataranutaporn et al. (2024), Wallace et al. (2023), Kaur et al. (2025), Zhou et al. (2025). Newer systems include language-model guidance, editable generation, duet motion and robotic performance Wang et al. (2025), Liu et al. (2025), Ghosh et al. (2025), Zhang et al. (2025), De Filippo et al. (2026).
Another reason why AI and dance should be studied is that no single technical architecture or paradigm of interaction dominates the field anymore. Transformers, masked-token models, diffusion pipelines, motion-editing interfaces, vision-based correction systems, XR heritage environments, and language-guided choreography tools now co-exist. Each of these codes another assumption of the nature of dance. A music-to-motion generator presupposes that dancing can be trained as a cross-modal map between the structure of sounds and the sequence in the body. A correction system presupposes that knowledge can be formalized in terms of deviation of a reference performance. A co-improvisation system presupposes that meaning of the movement is created in response to each other instead of predicting the entire sequence of the movement. A heritage system presupposes that the knowledge about dance does not limit itself to skeletal coordinates but includes context, narration and social memory. By comparing cases under these assumptions, it becomes feasible to discuss the field more precisely than the term AI in dance is a blanket term that would permit.
The article, too, is placed in a larger interdisciplinary discussion of the way performance ought to react to generative AI. Theatre and dance scholars have suggested that contemporary performance is a productive location when exploring the technogenesis, mediation, and evolving ideas about the body in the conditions of computationality Marx (2024). HCI researchers collaborating with dancers also demonstrate that co-creative technologies are a success or a failure not only due to the quality of models, but also due to expectations, workshop design, the visibility of system intention, and the affordances provided to performers Wallace et al. (2023), Liu (2024). Another angle is educational research: AI systems do not necessarily have to be creators, but can be scaffolds, diagnostic tools, or mirrors on which to build embodied skill Wang (2024), Xu et al. (2026). Such lines of work imply that a technical article in the field of dance studies should not separate model performance out of the larger ecology of use.
This growth poses a conceptual issue. Dance is not a mere series of poses in order. It is embodied art the meaning of which is based on timing, momentum, weight, address, memory, relation and interpretation. A system can produce persuasive motion paths and still not aid choreographic will, expression, and mutual agency. On the other hand, a system can produce new sequences but in a way that displaces the authorship of the dancer, flattens stylistic difference or deprives cultural practices of movement of the contextualization of their significance. Such issues are usually recognized in the existing technical papers, but they are not made to be the focus of system design. Their primary evaluation measures are beat alignment, distributional similarity, diversity or realism. Those measures are good, but they do not provide us with enough information about what sort of intelligence is being instantiated.
The social meaning of AI in the arts contributes to the intensification of the problem. Empirical studies indicate that audience and expert ratings depend on the belief that a work is computer generated despite the output being visible being kept constant Darda et al. (2023). Research on AI art perception also indicates that individuals tend to disassociate novelty and authenticity, rewarding technological surprise and doubting the richness of human creativity when machine involvement seems to be overpowering Bruen et al. (2025). The paradigm of human-computer interaction has changed to focus more on collaboration, where agency is distributed, negotiated, and interface-dependent, not being in either the human or the system Jiang et al. (2024), Krakowski (2025). Dance renders this problem abnormally tangible since choreographic agency is embodied in the body: in the initiation, response, correction, hesitation and co-presence. Any technical description of AI in dance which does not consider the politics of the body of control is thus not complete.
Because of this reason, the current paper discusses AI in dance by considering the concepts of embodied intelligence and algorithmic expression, which are connected. Embodied intelligence in this context is the extent to which a system involves dance as a knowledge of the body, as a place and as a relationship, as opposed to a general movement pattern. Algorithms expression. The technical expression of expressive intent, conditioned, generated, transformed or negotiated using computational models and interfaces. These ideas enable a more specific question than the general query of whether AI is good to dance. The question is what types of embodiment and expression can be supported by a system, what types it cannot support and how those are organized technically.
The article thus is not written like a typical review paper. Rather, it is composed as a typical technical research paper on the basis of an original multiple-case analytic data. Fifteen published systems published in 2021-26 were chosen as cases and coded using a common matrix. The cases are divided into four problem classes, namely, generation and transformation, training and correction, live co-performance and heritage/cultural mediation. Since the research is a document-based work and is concerned with system architecture, interaction logic, and evaluation design, it can generate a true method and results section without coming up with participant data or purporting to have done fieldwork. It is unique in terms of the corpus of cases, the coding scheme, the comparative study and the technical model obtained as a result of the comparative study.
The study is guided by three research questions. To begin with, what are the dimensions of embodiment that are implemented in the current AI-dance systems? Second, what is the specification and distribution of expressive control among models, prompts, interfaces and performers? Third, what design patterns are used to differentiate systems that only synthesize dance-like movement with systems that support more rich forms of choreographic intelligence? To address these questions, the article suggests a four-layer model of embodied intelligence comprising of kinematic, semantic, relational and cultural layers. It subsequently arrives at a five-part model of algorithmic expression that focuses on bodily alignment, semantic articulation, responsiveness between, contextual grounding and reflexive human supervision. The larger thesis is that the future AI-dance studies should be evaluated not only by the degree of realism of movement, but also by the degree of responsibility and meaning of its participation in the ecology of embodied performance.
2. Method
This research took a multiple-case technical design which was based on documents. Each discrete AI-dance system, platform, or model family was the unit of analysis, and was described in a primary technical source. The design was selected as the research problem relates to the operationalization of embodiment and expression within systems and not the discussion of these phenomena within only secondary commentary. Multiple-case approach allows cross-case comparison without loss of heterogeneity in architecture, interface, purpose and evaluation. It is thus suitable to a usual research paper that aims to attain novel findings of a systematic analytic dataset but not a narrative summary.
The identification of the cases was based on the primary sources published in 2021-2026. Search and selection was based on peer-reviewed journal articles, conference papers, and proceedings papers, preprints containing explicit technical detail, and project pages where they described model pipelines or interaction design in a way clear enough. A case was required to satisfy four conditions to be included: it must have been a dance-centred system as opposed to a generic human-motion system; it must have had an identifiable AI component or algorithmic decision process; it must have given a clear input-output relation or interaction process; and it must have had sufficient technical documentation to support structured coding. Papers that only comment but do not provide technical or interaction detail, duplicate reports of the same system and sources that do not provide technical or interaction detail were filtered out.
This article has a methodology that indicates that ecology. The case corpus is technical, but does not read models as neutral computational artefacts. It interprets them as socio-technical choreographic practices: as assemblies of data, goals, interfaces, assessment options and presumed users. This implies that even a conference paper and a practice-based system can be compared when they both detail how AI is involved into the dance process. This is not done to homogenize them, but to reveal their points of convergence and divergence in their logics. This method is particularly applicable to a rapidly changing discipline where preprints, demos, workshops, journal articles, and heritage platforms are all shaping the perception of AI that dancers and researchers have.
The corpus of the last case consisted of fifteen cases. The cases of generation and transformation consisted of AI Choreographer, Music-Driven Group Choreography, Multimodal Dance Style Transfer, DanceChat, DGFM, DuetGen, and DanceEditor Li et al. (2021), Le et al. (2023), Yin et al. (2023), Wang et al. (2025), Liu et al. (2025) The cases of training and correction involved Let All Dance and subsequent feedback-based systems Zhou et al. (2023), Cao (2026). Human-AI Co-Dancing, real-time full-body interaction, and LuminAI-oriented improvisation studies were examples of live co-performance case studies Pataranutaporn et al. (2024), Kaur et al. (2025), Zhou et al. (2025). The cases of heritage and culture involved DanXe and Text2Tradition Stacchio et al. (2024), Pataranutaporn et al. (2025). Large-language-model-assisted robotic dance creation was also a part of the corpus since it translated choreographic intent into embodied action via a hybrid human-AI control pipeline De Filippo et al. (2026).
A matrix that was created to code each case was used to code the cases. There were six major technical dimensions that were documented: primary objective, input modality, output form, interaction mode, and control locus and evaluation regime. Moreover, the cases were rated in four levels of embodiment. The kinematic layer was used to denote the explicit modelling of the fidelity of bodily motion, time coordination, pose plausibility, or movement continuity in the system. The semantic layer revealed the acceptance or maintenance of higher-level expressive descriptors like style labels, textual prompts, choreographic instructions, or interpretable feedback categories, by the system. The relational layer denoted the presence of a reciprocal relationship with another embodied agent e.g. duet interaction, group coordination, live response or turn taking. The cultural layer was a direct reference to a named tradition, archive, heritage corpus, or rule system which was associated with a particular movement culture.
Coding was deliberate conservative. Only when the primary source identified an embodiment layer as a substantive technical concern and not an incidental by-product, was a case considered positive with regard to the layer. As an example, semantic control was not necessarily considered to be music conditioning unless some meaningful high-level descriptors, editable prompts, or interpretable expressive guidance were also introduced by the system. In the same way, several dancers were not necessarily regarded as relational unless the model touched on interdependence, synchronization, responsive exchange or coordinated spacing. The rule minimized the inflation in the coding process and discriminated the comparative patterns.
In order to facilitate cross-case comparison, an Embodied Intelligence Index (EII) was made simple by adding the four layers of embodiment of each case, and this resulted in a score between 1 and 4. The index is not a statement of the artistic quality in an absolute sense. Instead, it is a comparative tool of finding the position of a system in the embodiment spectrum. Even a high-performing motion generator can be scored narrowly in case it is worried nearly solely with kinematic fidelity. In comparison, a system that incorporates live reciprocity or heritage rules can have a higher score in general, despite generating a lower amount of output. The EII was thus construed and compared qualitatively as opposed to being a standalone measure.
The analysis was in three phases. To map the distribution of the objectives, interaction modes, control structures, and embodiment layers, first, the case corpus was used to generate descriptive statistics. Second, the cases were read in comparison to discover technical trade-offs, common design patterns and blind spots of evaluation. Third, these patterns were synthesized to an interpretive frame of expression of algorithms in dance. The graphs and summary tables in the results section are original analytic outputs of the coding matrix created in this article, and are not a reproduction of the quantitative results of any source article.
The study has methodological limitations which are evident. Since the analysis is based on published documentation, it is not able to directly examine proprietary training pipelines or un-documented engineering choices. The corpus has also a variety of publication genres, including both archival journal articles and more recent preprints and conference papers, implying that the amount of detail is not exactly the same. These constraints were tolerated due to the fact that the object of interest is the public technical logic of AI-dance systems: the architectures, interfaces, and evaluative assertions in which such systems position themselves to researchers, dancers and audiences. The published configuration of a system is in this sense a part of the phenomenon under analysis.
Lastly, the paper takes note of control locus since agency in AI-dance is frequently talked about in the abstract when it is in fact implemented in the concrete through interface and workflow. A system with a single claim to authorship is very different when compared to a system with iterative editing, live response, selective acceptance, or embodied negotiation in performance. Control may change between phases: data preparation, training, prompting, curation, execution, revision and interpretation. Determining control as AI-dominant, human-dominant, or a combination of the two at the publicly documented system level can thus be used to map philosophical discussions of authorship into patterns that can be analyzed technically.
Figure 1
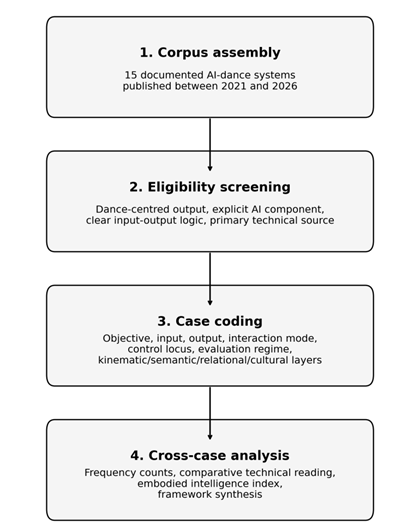
Figure 1 Methodological Workflow Used to Construct and Analyse the Case Corpus.
Table 1
|
Table 1 Analytic Corpus of AI-Dance
Systems Included in the Study |
||||
|
Case |
Year |
Primary objective |
Core input |
Interaction mode |
|
AI
Choreographer |
2021 |
Generation/transformation |
Music |
Offline
generation |
|
Music-Driven
Group Choreography |
2023 |
Generation/transformation |
Music +
spatial trajectory |
Offline
generation |
|
Let's All
Dance |
2023 |
Training/correction |
Amateur
motion + reference motion + music |
Interactive
correction |
|
Multimodal
Dance Style Transfer |
2023 |
Generation/transformation |
Video/motion
style cues |
Offline
transformation |
|
DanXe |
2024 |
Heritage/cultural |
Archival
multimedia + XR |
Interactive
exploration |
|
Human-AI
Co-Dancing |
2024 |
Live
co-performance |
Human
movement + virtual partner |
Live
co-performance |
|
Real-Time
Full-body Interaction with AI Dance Models |
2025 |
Live
co-performance |
Live
motion capture |
Live
improvisation |
|
Studying
Dancers' Perceptions of a Co-Creative AI in Improvisation |
2025 |
Live
co-performance |
Live
movement |
Live
improvisation |
|
DanceChat |
2025 |
Generation/transformation |
Music +
LLM guidance |
Offline
generation |
|
DGFM |
2025 |
Generation/transformation |
Music
foundation features + text |
Offline
generation |
|
DuetGen |
2025 |
Generation/transformation |
Music |
Offline
generation |
|
DanceEditor |
2025 |
Generation/transformation |
Music +
open-vocabulary text |
Interactive
editing |
|
Text2Tradition |
2025 |
Heritage/cultural |
Text
prompts + cultural rules |
Interactive
co-creation |
|
Robotic
Dance Creation with LLMs |
2026 |
Live
co-performance |
Language
prompts + robot control |
Interactive
co-creation |
|
AI-Based
Dance Movement Correction and Feedback |
2026 |
Training/correction |
Real-time
movement sensing |
Interactive
correction |
Table 2
|
Table 2 Coding Dimensions Used for the Cross-Case Technical Analysis |
||
|
Dimension |
Operational definition |
Examples in the corpus |
|
Kinematic
layer |
Explicit
modelling of pose plausibility, rhythm, trajectory continuity, or bodily
coordination. |
AI
Choreographer; Music-Driven Group Choreography; Let’s All Dance |
|
Semantic
layer |
High-level
expressive control through style labels, text prompts, interpretable
descriptors, or feedback categories. |
Multimodal
Dance Style Transfer; DanceChat; DGFM; DanceEditor |
|
Relational
layer |
Reciprocity
with another embodied agent, including duet interaction, live response, or
turn-taking. |
Human-AI
Co-Dancing; DuetGen; real-time full-body
interaction; LuminAI studies |
|
Cultural
layer |
Grounding
in a named dance tradition, archive, or culturally specific rule set. |
DanXe;
Text2Tradition; heritage-oriented co-performance |
|
Control
locus |
Where
documented system control primarily resides during use: AI-dominant,
human-dominant, or shared. |
Offline
generation often AI-dominant; correction systems human-dominant; live systems
shared |
3. Results and Discussion
The dominant presence of the systems of generation and transformation is the first pattern that can be observed in the corpus. Seven out of the fifteen cases, as Figure 2 reveals, were mainly categorized under this category, with four live co-performance systems, two training/correction systems and two heritage/cultural systems. This observation points to the fact that the majority of recent technical work has been focused on the generation and manipulation of dance-like product as opposed to pedagogy, mutual improvisation, and cultural mediation. Output synthesis continues to be the center of gravity of the field. In even the systems that purport to be creative or collaborative, most are structured around the challenge of producing completed motion sequences based on music or some other input.
This is a distribution that can be explained in terms of engineering. Generation tasks can be effectively fit into modern machine-learning workflows: they have access to large datasets, have well-defined input-output mappings, can be trained at scale, and are evaluated quantitatively. Particularly, music-conditioned choreography presents a manipulable multimodal issue where rhythm, tempo and structure may be combined with body movement. But the focus of energy on generation also defines what is considered as progress. Embodied intelligence when the technical frontier is characterized by synthesis is likely to be gauged in terms of realism, musical fit, diversity, and smoothness. They are precious properties, but they tend to make dance what can be effectively forecasted.
Figure 2
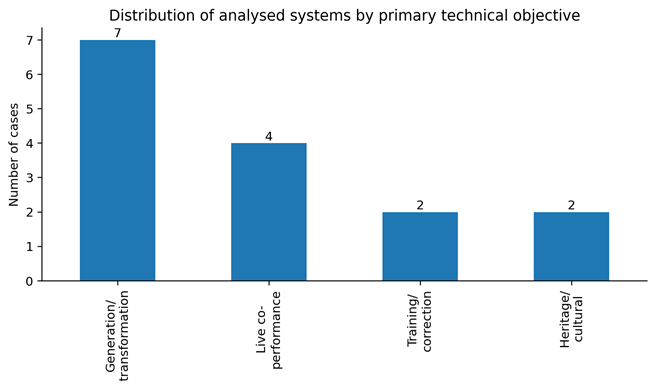
Figure 2 Distribution of Analysed Systems by Primary
Technical Objective.
The coding matrix indicates that the kinematic intelligence is nearly universal in the corpus. Bodily movement fidelity, timing, trajectory coherence, pose plausibility or motion continuity were explicitly covered in fourteen out of fifteen cases. This was not surprising, since almost all modern systems have to address a low-level problem of bodily plausibility, just to be plausible at all. This dominance is seen in Figure 4. Semantic intelligence also had a strong representation as it was seen in eleven instances. In this case, the field has made significant progress over the last two years, with systems adding more and more style labels, text prompts, interpretable descriptors or language-model mediation. In comparison, relational intelligence was only found in six instances and cultural grounding in three.
This is significant in terms of uneven distribution. It implies that the field has been able to become more and more able to tell a model what sort of dance it should produce, but far less able to construct systems which are actually responsive, related, or placed in cultural context. Semantic control is scaling more rapidly than reciprocity or contextual grounding, in technical terms. Language models are capable of producing pseudo-choreographic instructions, text-condition motion priors, or can help with editing interfaces with relative ease. When it comes to constructing systems that are sensitive to the presence of another body and negotiate turn-taking, or even maintain the symbolic logic of a particular dance tradition without simplifying it to a generic feature set, it is far more difficult. In this way, the present AI-dance system is shifting towards more semantically rich than merely kinematic systems, but not to widely situated intelligence.
This is further explained in the interaction-mode profile in Figure 3. The only form of interaction that is the most prevalent is offline generation, which is closely linked to the AI-dominant control. The model is often placed as the key source of movement in these systems, with the human role being to curate data, promptly engineer, select a model, or post-hoc evaluate. The shared control is significantly more widespread as soon as interaction is live, editable, or co-creative. Interactive editing, live improvisation, co-performance and heritage exploration all demand interfaces where the human retains or reclaims significant control over timing, selection, interpretation, or performance. Control is thus not a predetermined aspect of AI in dance. It is highly dependent on the point of choreography workflow insertion of the system.
Figure 3
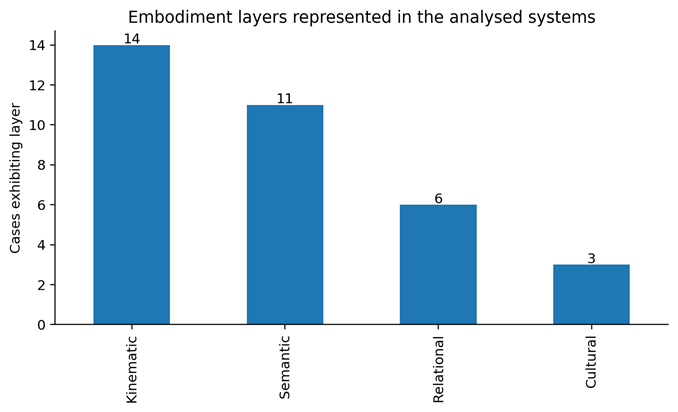
Figure 3 Embodiment Layers Represented Across the Analyzed Systems.
Another historical stratification of research ambitions is also revealed in the comparative dataset. The initial efforts were aimed at demonstrating the possibility of AI creating believable dance movement at all. When that limit was reached, researchers proceeded to complexity: group choreography, style transfer, duet dynamics, editability and text conditioning. The following frontier seems to be two challenging transitions. One is generation to collaboration: the systems that generate dance to the systems that are involved in choreographic process. The other is generic movement intelligence to situated embodiment: systems that move convincingly to those that move meaningfully within a particular artistic or cultural frame. The results that are presented below can be interpreted as the evidence that the first transition is taking place, whereas the second one is uneven.
The other common pattern of the corpus is related to the scale and specificity. The extensive datasets like AIST++ and AIOZ-GDANCE have obviously fostered technical progress since it is now possible to generate longer sequences and perform group modelling Li et al. (2021), Le et al. (2023). But massive success may conceal the reality that there is a great deal of ontological and transmission variation in dance practices. A model that has been trained on the wealth of modern performance videos could be successful in its rhythmic diversity and unaware of ritual sequence, norms of pedagogic correction, or embodied symbolism in classical and vernacular modes. This is one of the main reasons why the cultural layer is present in the coding model as this tension between scale and specificity is one of the key ones. In its absence, data-rich systems with context-thin systems would seem more complete than they are.
Figure 4
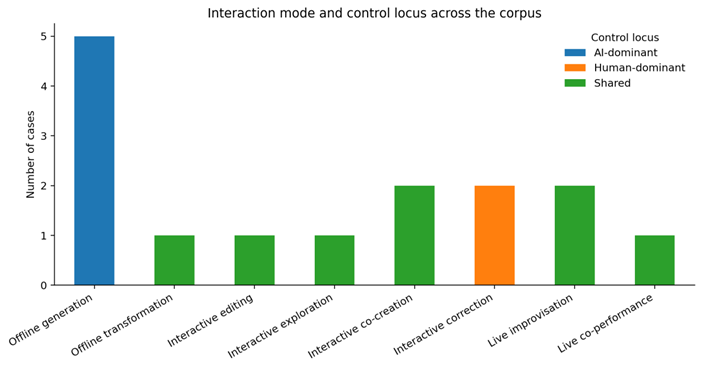
Figure 4 Interaction Mode and Control Locus Across the Analytic Corpus.
The Embodied Intelligence Index supports the observation. The instances which had the highest EII scores were those which were directed towards live reciprocity or culturally based co-performance as opposed to those that produced the greatest amounts of motion. Human-AI Co-Dancing scored the highest since it integrated the output of the body, semantic framing, relational exchange and cultural heritage orientation in a single interactive concept. The research of DanXe and LuminAI-based improvisation also received a high score as they went beyond the aspect of motion quality to interpretation, exploration, or mutual interaction. In comparison, AI Choreographer, with its historical significance and excellent technical input, received a very close score since its popular technical logic is focused on kinematic music-to-motion generation as opposed to more general layers of embodied meaning.
The second key result is related to the diversification of input design. The initial systems were mainly dependent on music as the prevailing conditioning signal. The models of AI Choreographer and subsequent music-driven generation learn the patterns of movement based on audio characteristics, rhythm, or previously taught multimodal associations Li et al. (2021), Le et al. (2023). With the maturation of the field, there were increased heterogeneity of inputs. Systems have been integrated with music and textual prompts, style cues, spatial paths, real-time motion capture, duet context, archival content, or language-model-generated instructions. DanceChat specifically leverages a large language model to connect music and dance by generating interpretable choreographic directions, and DGFM builds on conditioning with music-foundation capabilities and text Wang et al. (2025), Liu et al. (2025). DanceEditor and other editable systems do not view language as a peripheral layer of annotation but as a control surface to be iteratively edited.
This change has a technical and aesthetic implication. In technical terms, multimodal conditioning can be used to address the underdetermination issue of music-to-dance mapping: a single musical input can be used to legitimately support a large variety of different movement realizations. Other signals reduce the expressive search space but not completely. Aesthetically, emergence of textual and semantic controls recognizes that dance is not all about beat tracking. Attack, softness, suspension, intimacy, rituality or dramatic escalation are some of the concepts that choreographers usually work with. All of them cannot be retrieved by means of audio. As soon as the textual or interpretable descriptors are introduced into the system, the expression of algorithms can be articulated more, edited more, and even held to responsibility.
The design of output has been diversified. The previous systems tended to generate a full-fledged dance sequence or an avatar image. More recent systems generate editable motion, partner-aware motion, embodied feedback cues, robotic enactment, immersive heritage layers or response-based co-performance. It is not such a small shift in presentation format. It indicates a more profound change in the conceptualization of the role of the system. Choreography is modeled as an optimization problem in a model that produces a complete sequence. A model which yields editable content models choreography as a design space which is iterative. A system which reacts to a live dancer considers choreography as relational emergence. Heritage interface views dance as stratified cultural information as opposed to motion capture.
Such differences in design also contribute to the reason why the evaluation regimes in the corpus are still heterogeneous. Generation papers are generally objective metrics, distributional comparisons, alignment scores, and sometimes user studies. Training and correction systems are prone to confound computational analysis with practical use or improvement-focused testing. Live co-performance work is more dependent on practice-based analysis, workshops, thematic interviews or reflective design practices. Heritage systems tend to justify their input as expert interpretation, value of the curator or human-in-the-loop annotation success, as opposed to a single scalar standard. This variety is not a drawback of the field; it is an implication of the fact that the AI-dance systems address various types of problems. But it does pose a danger in the importation of performance measures that have been constructed in one type of problem into another without a critical evaluation.
Take into consideration the difference between generation and improvisation. Repeatability and comparability of benchmarks is desirable in offline generation. In live improvisation, surprise, responsiveness, latency tolerance, or the perceived ability of the dancer to negotiate with the system in real-time may be critical to the success of a system. A slightly inferior co-improvisational partner according to benchmark criteria can still prove more artistically helpful than a highly refined generator which is incapable of responding. The studies that are oriented towards LuminAI are particularly useful in this case because they help to revert to the experience of the dancer: how the AI is perceived, when it becomes catalytic, when it becomes constraining, and how improvisational practice transforms when partnering with machines Wallace et al. (2023), Kaur et al. (2025). Beat alignment is not sufficient to answer these questions.
The third significant conclusion is related to the connection between authorship and editability. In most studio situations, the choreographers do not desire a model to provide an ultimate solution. They desire the model to give material that can be revised, cut, recombined, amplified or contradicted. The dance generation systems like DanceEditor and Walk Before You Dance are heading towards this new frontier between autonomous generation and usable choreographic support. Redistributes control over time. The system can be AI-dominant at the time of the initial synthesis, but can be far more aligned with shared agency when it allows human reinterpretation cycles to occur. In the view of algorithmic expression, editable systems are important in that they maintain the intentionality following generation. They enable expression to be negotiable as opposed to being determined by the first machine output.
Another crucial asymmetry in the area is unveiled in heritage-centred cases. Tacit pedagogies, ritual forms, embodied memory, costume practice, spatial conventions and culturally specific symbolic vocabularies are often dance traditions. This can be captured, in large multimodal datasets, although not all. The importance of DanXe and Text2Tradition lies in the fact that they do not want to translate heritage into coordinates of movements alone. They combine archival content, expertise, XR display, language interfaces, or rule-based instructions to maintain contextual meaning and bodily form. The fact that the cultural grounding was only found in three cases of the corpus demonstrates how poorly this design space is developed yet. But it is among the most significant fields of future work, particularly in the environment of intangible cultural heritage.
This underrepresentation is not just a subject matter gap; it is a bias in data-intensive AI. The research frontier is dominated by what is simplest to capture, annotate and scale. Large-model training is more compatible with rehearsed performance sequences, beat-aligned motion clips or visually standardized dance videos than embodied practices that are transmitted through apprenticeship, community ritual or localized context. The systems that are heritage-oriented thus need hybrid solutions: machine learning and expert annotation, generative modeling and cultural rule sets, or interface design and curatorial mediation. The future AI-dance research cannot afford to use larger datasets solely in case it is serious about cultural diversity. It also needs to come up with more powerful ways of situated knowledge representation.
Collectively, these findings indicate that embodied intelligence within AI-dance systems is stratified, as opposed to homogenous. Kinematic alignment is now fairly developed. Semantic articulation is proliferating at a high rate by text conditioning and language-model mediation. Relational responsiveness is relatively limited and is limited to live systems. Cultural grounding is small-scale, localized and hard to scale. The domain is not then advancing in a straight line away toward the less advanced, to the more advanced. It is spreading out to various philosophies of dance that are technical. Dance is considered a sequence prediction problem by some systems; a corrective pedagogical problem by others; a live relational encounter by others; and a culturally mediated knowledge interface by others. It is important to identify these branches in order to have coherent evaluation, design, and criticism.
Based on these results, a technical expression of algorithm can be suggested. The initial is bodily alignment: a system should produce or process movement which is temporally consistent, physically plausible, and sufficiently detailed to make performance sense. The second is semantic articulation: the system should offer interpretable handles in which intention, style or expressive quality can be defined not just deduced ex post. The third one is reciprocal responsiveness: in which interaction is live or co-creative, the system should be responsive to another body as a situated partner, not just a source of data. The fourth one is contextual grounding: the expression of output must be rooted in the aesthetic, social or cultural frame within which the practice of dance is produced. The fifth is reflexive human supervision: dancers and choreographers have to be able to check, re-direct, rebuff or re-process machine output instead of giving up authorship wholesale.
These five requirements are not just philosophical, but technical. Bodily alignment determines model architecture, motion representation and physical priors. The interface design, prompt vocabulary, annotation strategy and controllable generation are influenced by semantic articulation. The sensing pipelines, latency constraints and turn-taking logic are formed by reciprocal responsiveness. The concept of contextual grounding influences dataset design, archival connection, specialist cooperation and cultural metadata. Reflexive human control influences editability, logging, selection processes and integration of workflow. A system does not have to optimize all five dimensions simultaneously, but the design decisions must explicitly state what dimensions it is used to serve and which dimensions it is left thin. This transparency would enhance the assessment of the system and interdisciplinary communication among the engineers, dancers, and arts scholars.
The bigger picture is that dance has provided AI research with more than a compelling field of application. Dance reveals the boundaries of an intellect of strictly representational nature. It helps us remember that movement is not just output, but relation; not just signal, but interpretation; not just data, but situated practice. The AI systems can be a potent addition to the world of dance by amplifying the choreographic imagination, creating new accessibility, or creating fruitful space of co-creation. They weaken as they become expression to pattern reproduction or as they make cultural movement knowledge a decontextualized style label. In this regard, the future of AI in dance is not so much about whether models are bigger and more autonomous but more about whether they are more embodied, dialogic, and responsible to the worlds in which dance is practiced.
A major implication of such trends is that the future of technical innovation in dance will most probably be hybrid and not monolithic. There is no best model family that is suited in all the choreographic tasks. The diffusion and masked-motion models seem to be potentially high-fidelity synthesis, language mediation can be applied to semantic control, XR interfaces can be used to access archives and heritage, and low-latency sensing is necessary in improvisation and pedagogy. Next-generation systems will most likely be based on a combination of these layers rather than a selection between them. An ecosystem of AI and dance would connect curated cultural knowledge, editable motion priors, interpretable prompts, real-time embodied sensing, and practitioner-centred assessment. It would not be to recreate an autonomous ideal choreographer, but to establish responsive infrastructures, based on which dancers, teachers, archivists, and audiences could operate with computational systems without losing the embodied particularity of dance as such.
Table 3
|
Table 3 Cross-Case Technical Coding Summary |
|||||||
|
Case |
Obj. |
Ctrl. |
Interact. |
Kin. |
Sem. |
Rel. |
Cult. |
|
AI
Choreographer |
Gen./transf. |
AI-dominant |
Offline
generation |
1 |
0 |
0 |
0 |
|
Music-Driven
Group Choreography |
Gen./transf. |
AI-dominant |
Offline
generation |
1 |
0 |
1 |
0 |
|
Let's All
Dance |
Training |
Human-dominant |
Interactive
correction |
1 |
1 |
0 |
0 |
|
Multimodal
Dance Style Transfer |
Gen./transf. |
Shared |
Offline
transformation |
1 |
1 |
0 |
0 |
|
DanXe |
Heritage |
Shared |
Interactive
exploration |
1 |
1 |
0 |
1 |
|
Human-AI
Co-Dancing |
Live
co-perf. |
Shared |
Live
co-performance |
1 |
1 |
1 |
1 |
|
Real-Time
Full-body Interaction with AI Dance Models |
Live
co-perf. |
Shared |
Live
improvisation |
1 |
0 |
1 |
0 |
|
Studying
Dancers' Perceptions of a Co-Creative AI in Improvisation |
Live
co-perf. |
Shared |
Live
improvisation |
1 |
1 |
1 |
0 |
|
DanceChat |
Gen./transf. |
AI-dominant |
Offline
generation |
1 |
1 |
0 |
0 |
|
DGFM |
Gen./transf. |
AI-dominant |
Offline
generation |
1 |
1 |
0 |
0 |
|
DuetGen |
Gen./transf. |
AI-dominant |
Offline
generation |
1 |
0 |
1 |
0 |
|
DanceEditor |
Gen./transf. |
Shared |
Interactive
editing |
1 |
1 |
0 |
0 |
|
Text2Tradition |
Heritage |
Shared |
Interactive
co-creation |
0 |
1 |
0 |
1 |
|
Robotic
Dance Creation with LLMs |
Live
co-perf. |
Shared |
Interactive
co-creation |
1 |
1 |
1 |
0 |
|
AI-Based
Dance Movement Correction and Feedback |
Training |
Human-dominant |
Interactive
correction |
1 |
1 |
0 |
0 |
4. Conclusion
This paper reviewed 15 recent AI-dance systems using a new multi-case technical structure that is based on embodied intelligence and algorithmic expression. It was found that the field is at present strongest in the area of kinematic modelling and is getting stronger in the area of semantic control, yet relatively weak in the areas of relational reciprocity and cultural grounding. Systems that were based on live co-performance and heritage mediation generated the most extensive embodiment profiles, whilst offline generators were still focused on the level of motion fidelity. These results indicate that the future of dance-AI cannot be determined by the ability of a model to imitate dance in a more realistic manner, but rather by the ability to facilitate embodied agency, interpretable control, contextual meaning, and human control.
The overall technical contribution of the article thus is both analytic and conceptual. It provides a useful set of vocabulary to design and analyze future systems, distinguishing between the kinematic, semantic, relational, and cultural layers of embodiment, and proposing a five-part system of expression of algorithms. This vocabulary helps researchers to understand whether they are developing generators, tutors, partners, editors or cultural interfaces and to determine what dimensions of dance intelligence their systems are focusing on or ignoring.
There are three priorities that should be undertaken in future research. To begin with, it ought to shift away realism metrics to evaluation protocols that encompass interpretability, reciprocity, and situated usefulness. Second, it ought to invest in workflows that can be edited and collaborative, which retain dancers and choreographers within the creative loop. Third, it must devise more powerful approaches to culturally based modelling in such a way that AI is involved in dance not just as a source of movement, but also as a preservation, pedagogical, and responsible artistic experimentation. To rethink dance in the era of AI, one must first rethink what intelligence is: not as a disembodied optimization, but as a movement, feeling, and responding, meaning process with others.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Archiwaranguprok, C., Marfia, G., and Stacchio, L. (2024). Open Dance Lab: Digital Platform for Examining, Experimenting with, and Promoting Dance Heritage. ACM Conference Companion on Designing Interactive Systems.
Baker, B. (2022). Creativity in AI Dance Art. CEUR Workshop Proceedings.
Bruen, J. E., et al. (2025). Knowledge of How AI Art Is Made Shapes Audience's Perceptions of Technologically Augmented Dance. Performance Research.
Cao, Y. (2026). AI-Based System for Dance Movement Correction and Feedback. ACM Digital Library.
Dai, Y., et al. (2025). TCDiff++: An End-to-End Trajectory-Controllable Diffusion Model for Harmonious Music-Driven Group Choreography. Proceedings of the AAAI Conference on Artificial Intelligence, 39(3).
Darda, K. M., et al. (2023). The Computer, a Choreographer? Aesthetic Responses to Computer-Generated Dance. Psychology of Aesthetics, Creativity, and the Arts.
De Filippo, A., et al. (2026). Fostering Human-AI Collaboration in Robotic Dance Creation With Large Language Models. International Journal of Human-Computer Studies.
Garzarella, S., Marfia, G., and Stacchio, L. (2024). Preserving and Annotating Dance Heritage Material Through Human-in-the-Loop Artificial Intelligence. CEUR Workshop Proceedings.
Ghosh, A., et al. (2025). DuetGen: Music Driven Two-Person Dance Generation via Diffusion Models. arXiv.
Gupta, P., et al. (2025). MDD: A Dataset for Text-and-Music Conditioned Duet Dance Generation. arXiv.
Huang, R. (2025). Transforming Dance Education in China: Digital Culture, AI Literacy, and Heritage Transmission. Research in Dance Education.
Jiang, J., et al. (2024). Human-AI Collaboration and Shared Agency: Toward a Framework for Co-Creative Systems. International Journal of Human-Computer Interaction.
Kaur, J., et al. (2025). Studying Dancers' Perceptions of a Co-Creative AI in Improvisation. ACM Creativity and Cognition.
Krakowski, S. (2025). Symbiotic AI: Reframing Agency, Control, and Responsibility in Collaborative AI Systems. Organization Theory, 6(1).
Le, N., Pham, T., Do, T., Tjiputra, E., Tran, Q. D., and Nguyen, A. (2023). Music-Driven Group Choreography. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8673–8682. https://doi.org/10.1109/CVPR52729.2023.00838
Li, R., Yang, S., Ross, D. A., and Kanazawa, A. (2021). AI Choreographer: Music Conditioned 3D Dance Generation With AIST++. Proceedings of the IEEE/CVF International Conference on Computer Vision, 13381–13392. https://doi.org/10.1109/ICCV48922.2021.01315
Liu, X., et al. (2025). DGFM: Full Body Dance Generation Driven by Music Foundation Model and Text. arXiv.
Liu, Y. (2024). Interaction Design for Human-AI Choreography Co-Creation. Generative AI and HCI Workshop.
Long, D., et al. (2020/2025). LuminAI: Embodied AI as a Catalyst, Constraint, and Co-Creative Partner in Movement Improvisation. Computational Creativity and HCI Project Materials.
Marin-Bucio, D. (2025). Enacting Dance Experience Through Human-AI Kinematic Co-Creation. HCI International Workshop Paper.
Marx, L. (2024). Choreographies in the World of AI. Theatre, Dance and Performance Training, 15(4), 547–560.
Nogueira, M. R. (2024). Exploring the Impact of Machine Learning on Dance Performance and Choreography. Digital Creativity, 35(3), 1–18.
Pataranutaporn, P., et al. (2024). Human-AI Co-Dancing: Evolving Cultural Heritage Through Virtual Co-Performance. ACM Designing Interactive Systems.
Pataranutaporn, P., et al. (2025). Text2Tradition: Human-AI Interface for Exploration and Co-Creation of Traditional Dance. ACM Designing Interactive Systems.
Shah, F. N., et al. (2025). Walk Before You Dance: High-Fidelity and Editable Dance Synthesis via Generative Masked Motion Pre-Training. arXiv.
Stacchio, L., Marfia, G., and Prandi, C. (2024). DanXe: An Extended Artificial Intelligence Framework to Analyze and Promote Dance Heritage. Digital Applications in Archaeology and Cultural Heritage, 33, e00336.
Vechtomova, O., and Bos, H. (2025). Reimagining Dance: Real-Time Music Co-Creation Between Dancers and AI. arXiv.
Wallace, B., et al. (2023). Embodying an Interactive AI for Dance Through Movement Workshops. ACM Creativity and Cognition.
Wang, Q., et al. (2025). DanceChat: Large Language Model-Guided Music-to-Dance Generation. arXiv.
Wang, Z. (2024). Artificial Intelligence in Dance Education: Using Immersive Systems to Support Technique and Choreography Learning. Technology in Society, 77, 102513.
Xu, S., et al. (2026). Effects of a Real-Time Interactive GenAI Dance Learning Environment on Dance Skills, Engagement, and Learning Motivation. Frontiers in Education, 11, 1756945.
Yin, W., Yin, H., Baraka, K., Kragic, D., and Bjorkman, M. (2023). Multimodal Dance Style Transfer. Machine Vision and Applications, 34(4), 48. https://doi.org/10.1007/s00138-023-01399-x
Zhong, Y. (2025). The Application of Artificial Intelligence Technology in the Dance Field: Core Technical System and Application Scenarios. Arts, 14(2), 27.
Zhou, J., et al. (2025). Real-Time Full-Body Interaction With AI Dance Models. ACM Conference on Human Factors in Computing Systems Extended Abstracts. https://dl.acm.org/
Zhou, Q., Li, M., Zeng, Q., Aristidou, A., Zhang, X., Chen, L., and Tu, C. (2023). Let’s All Dance: Enhancing Amateur Dance Motions. Computational Visual Media, 9(3), 531–550. https://doi.org/10.1007/s41095-022-0292-6
|
|
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© ShodhKosh 2026. All Rights Reserved.