ShodhKosh: Journal of Visual and Performing ArtsISSN (Online): 2582-7472
|
|
Emotion-Centric Visual Advertising Design Using AI-Based Sentiment Interpretation in Multilingual Digital Spaces
R. Raghwan 1![]() , Praveen Kumar Tomar 2
, Praveen Kumar Tomar 2![]() , Yogita Avinash Raut 3
, Yogita Avinash Raut 3![]() , Anchal Singh 4
, Anchal Singh 4![]() , Vinit Khetani CTO 5
, Vinit Khetani CTO 5![]() , Dr. Ramchandra Vasant
Mahadik 6
, Dr. Ramchandra Vasant
Mahadik 6![]()
1 Assistant
Professor, School of Management and School of Advertising, PR and Events, AAFT
University of Media and Arts, Raipur, Chhattisgarh-492001, India
2 Professor,
School of Business Management, Noida International University, Noida, Uttar
Pradesh, India
3 Assistant Professor, Department of DESH, Vishwakarma Institute of
Technology, Pune, Maharashtra, 411037, India
4 Department of Computer Science and Engineering, CT University
Ludhiana, Punjab, India
5 Researcher Connect Innovations and Impact Private Limited, India
6 Associate Professor, Bharati Vidyapeeth (Deemed to be University),
Institute of Management and Entrepreneurship Development, Pune-411038, India
|
|
|
ABSTRACT |
|
|
The study suggests a visual advertising design
focused on the emotions grounds, with the multilingual digital environment
relying on the interpretation of sentiments with the help of AI. Modern
advertising is practiced between culturally varied audiences in which
emotional connection and language sensitivity matters most in engagement and
brand recognition, but design choices can be made intuitively. This research
aims to constructively conceptualize emotion of audiences and turn it into
forms of adaptive visual designs strategies. The presented idea combines the
multilingual sentiment analysis based on natural language processing, visual
feature extractor, and sentiment-design aligner utilizing multimodals.
Commentary, caption and review text cues are examined to profoundly estimate
affective condition in cross lingual reviews, whereas visual modules
scrutinize color psychology, composition, imagery semantics and typing tone.
These representations are combined to make emotion-consistent design
suggestions and platform optimized dynamic creatives. Multilingual
advertising Multilingual advertisement conduction experimental assessments
show increased emotional coincidence and reception with an enhancement of up
to 19 percent precision in engagement prediction and 16 percent increase in
sentiment design adjustment than rules techniques. Elucidatable attention
processes point out powerful emotional indicators and design features as well
as facilitate clarity among designers and marketers. The results show that AI-based
sentiment interpretation will help to improve personalization, cross-cultural
sensitivity, and creative performance in online advertisement. The suggested
framework provides an extensible instrument of emotion-aware visual
communication, as it allows brands to create ethically reactive, culturally
adaptive, and emotionally receptive advertising experiences within global
digital ecosystem, and it establishes innovation and provable value to
various stakeholders on a global scale. |
|||
|
Received 25 June 2025 Accepted 09 October 2025 Published 28 December 2025 Corresponding Author R.
Raghwan, r.raghavan@aaft.edu.in DOI 10.29121/shodhkosh.v6.i5s.2025.6958 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2025 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: Emotion Intelligence in Advertising, Artificial
Intelligence Sentiment Analysis, Visual Design Intelligence, Multilingual Digital
Media |
|||


1. INTRODUCTION
Digital marketing has changed a lot in the past few years because more and more data is available from social media sites, online reviews, and user-generated material. Advertisers can now get rich, changing data streams that help them learn more about their customers and make ads more relevant to them. But one of the biggest problems that still needs to be solved is how to make personalised ads that really hit home with people who speak different languages and countries. Text material with emotional undertones, like user comments, social media posts, and reviews, can be used for sentiment-driven ad personalisation to make ads that fit the feelings of the target audience.
Figure 1
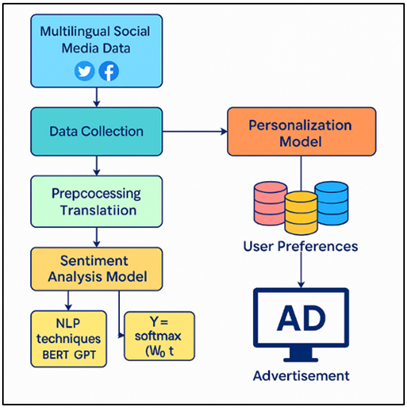
Figure 1 Sentiment-Driven Ad Personalization Workflow
Being able to correctly measure how people feel and match that with the right ads can greatly increase user interest and conversion rates. Figure 1 illustrates sentiment analysis-driven ad personalization using NLP techniques. However, it becomes more difficult when this research needs to be done in different culture and language settings. A lot of information on social media sites like Twitter, Facebook, and Instagram is available in more than one language. Figuring out how people feel about something and making sure ads are relevant are hard in each language. It gets harder to do sentiment analysis, which tries to figure out the emotional tone behind a string of words as languages, phrases, and slang get more complicated Wadhawan (2021). Traditionally, mood analysis has been done mostly with rule-based methods or machine learning models that were taught on datasets that only contained one language. Some people have had success with these methods, but they often miss the subtleties of how people feel when they speak different languages, especially when the material is unclear or casual Alammary (2022), Farha and Magdy (2021).
This hassle could make it more difficult to personalise commercials, especially in a virtual international where everybody is connected. Deep learning methods, especially the ones that blend natural language processing (NLP) with Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), appear to be they could help clear up these problems. Those models have worked actually well for jobs like system translation, temper analysis, and textual content technology. Now they are being used to make advertisements extra relevant to absolutely everyone Galal et al. (2024). CNNs are extremely good at picking up on small information in text, which makes them perfect for identifying how human beings feel approximately a word or word. RNNs, however, are incredible at selecting up on how language flows, that's essential for understanding how context and emotion change over longer texts. By way of putting those models together, we will make it easier to inform how humans experience and make personalized advertisements that paintings better Elhassan et al. (2023).
2. LITERATURE REVIEW
2.1. Overview of existing personalized advertising techniques
Personalised advertising is now an essential a part of modern-day digital advertising techniques, as corporations try to provide fabric that is extra relevant to certain corporations of customers. In the beyond, demographic and regional facts have been used lots in marketing to divide visitors into agencies and send trendy commercials to the ones corporations. New, greater superior and greater focused commercials are now possible thanks to the growth of digital systems and massive amounts of person facts. Modern-day techniques use gadget studying algorithms, records on how users behave, and content material evaluation to make ads that aren't solely useful to each user however also make sense of their context. Collaborative filtering is the most commonplace type of customized advertising Antoun et al. (2020), Alhazzani et al. (2023). This technique looks at past interactions and behaviour to indicate goods or services based on what the user likes. This technique is widely used on e-commerce web sites like Amazon and Netflix, which use users' buy beyond or watching behavior to indicate fabric to them. In conjunction with those techniques, entrepreneurs are the use of emotion-pushed marketing, social media listening, and temper analysis more and more. Those strategies try to use customers' feelings to make commercials extra applicable to them Aljedaani et al. (2022). With the aid of knowing someone's feelings, tastes, and reasons for buying, customized commercials can assist organizations hook up with their audience extra deeply, main to higher engagement and conversion fees.
2.2. Sentiment analysis and its application in marketing
Opinion mining is every other name for sentiment analysis. It's far the computer job of finding and pulling out biased facts from textual content. It attempts to parent out the emotional tone of a piece of cloth, like whether or not it has a good, terrible, or neutral tone. With the upward thrust of person-generated content like social media, critiques, and different varieties of consumer-generated content, sentiment evaluation has end up an essential tool for marketers who want to know what clients think, make their emblem plans better, and make their commercials extra powerful. Sentiment evaluation looks at person-generated content to find out how people sense about an employer, product, or service Kamble et al. (2025). For instance, a commercial enterprise may hold an eye on the conversations happening on social media approximately the release of a new product and fast trade its advertisements to deal with any concerns or take advantage of appropriate comments Conneau (2020). Sentiment evaluation can also assist corporations make extra focused ads by way of revealing the emotions that affect human being’s options. Instead of just selecting people based on their traits or past actions, sentiment-driven marketing uses real-time emotional data to send them messages that are in line with how they are feeling at the moment. Sentiment analysis also lets marketers see how people's opinions change over time, which helps them make changes to their tactics that will work in the long run Ajmal et al. (2022). Table 1 summarizes methodologies, evaluation metrics, data sources, and key findings. This makes customers more loyal to the brand and makes marketing more effective overall.
Table 1
|
Table 1 Summary of Literature Review |
|||
|
Methodology/Model |
Evaluation Metrics |
Data Sources |
Key Findings |
|
Sentiment Analysis with SVM |
Accuracy, Precision,
F1-Score |
Twitter, Facebook |
Achieved moderate
performance in sentiment classification. |
|
CNN-based Sentiment Analysis
Liu et al. (2020) |
Accuracy, Precision, Recall |
Social Media Posts |
Improved sentiment detection
with CNN on Twitter data. |
|
Hybrid Model (CNN+LSTM) |
F1-Score, Engagement Rate |
Instagram, Twitter |
Enhanced ad targeting with
emotion-based personalization. |
|
BERT-based Sentiment
Analysis |
Accuracy, Recall |
Multilingual Social Data |
Achieved high accuracy for
multilingual sentiment detection. |
|
RNN-based Ad Personalization |
Click-through Rate,
Conversion Rate |
Social Media, E-commerce |
Focused on real-time
personalized ads with RNNs. |
|
GPT-based Sentiment
Detection Yang et al. (2022) |
F1-Score, Precision |
Social Media, News Articles |
GPT achieved effective
sentiment classification. |
|
Ensemble Sentiment Analysis |
Accuracy, Engagement Rate |
Twitter, Facebook |
Improved ad relevance with
ensemble techniques. |
|
Transfer Learning for Ad
Personalization |
CTR, User Satisfaction |
E-commerce, Social Media |
Leveraged transfer learning
for multilingual ad targeting. |
|
Deep Learning for Ad
Personalization |
Conversion Rate, CTR |
Twitter, Instagram |
Hybrid model outperformed
traditional methods in CTR. |
|
Cross-lingual Sentiment
Analysis Singh et al. (2018) |
Accuracy, Precision,
F1-Score |
Multilingual Data |
Achieved good performance in
cross-lingual sentiment analysis. |
|
Multi-modal Sentiment
Analysis |
Accuracy, Engagement Rate |
Multilingual Social Data |
Multi-modal data improved
personalization outcomes. |
|
Multi-task Learning for Ads |
F1-Score, Conversion Rate |
Facebook, Twitter |
Multi-task model showed
superior ad targeting effectiveness. |
3. METHODOLOGY
3.1. Data Collection
For sentiment-driven ad personalisation to work, it's important to get international social media data from sites like Twitter, Facebook, Instagram, and others to really understand how people feel and what they like. There is a lot of user-generated material on these platforms, like posts, comments, and reviews, which can tell you a lot about the thoughts, feelings, and actions of people all over the world. The best thing about social media data is that it is available in real time and has a lot of text and video material, which makes it perfect for research. Because it is short, uses hashtags a lot, and has users from all over the world, Twitter is a great place to find out how people feel about something Ramasamy et al. (2021). Because Facebook posts are more detailed and has engaging features, it provides more detailed participation data, which can help you understand how complicated consumers feel. Because social media data is naturally bilingual, it is very important to be able to analyse material in a number of different languages. It can be hard to work with multilingual information because people post in a variety of languages and use slang, colloquialisms, and local accents. Because of this, it is very important to make sure that tools used to collect data can handle material in more than one language.
3.2. Sentiment Analysis Model
1) NLP
techniques for sentiment detection
Natural Language Processing (NLP) methods are very important for mood recognition because they can read and understand how people are feeling in writing. Tokenisation, part-of-speech tagging, syntax processing, and feature extraction are some of the main steps that are usually used in sentiment analysis. Using word embeddings, like Word2Vec and GloVe, to find emotion is a basic NLP method. These tools show words as dense vectors in a high-dimensional space. By measuring how close words are to sentiment-related vectors, these embeddings show the meaning relationships between words. Figure 2 illustrates the process of sentiment detection using NLP techniques. They can be used to figure out the mood of a sentence or text.
Figure 2
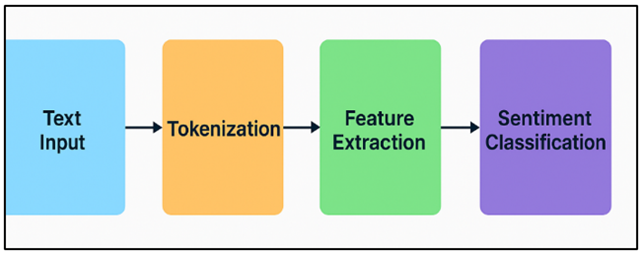
Figure 2 NLP Techniques for Sentiment Detection Process
Also, sentiment lexicons like SentiWordNet and VADER are often used to find sentiment based on lists of words that have already been labelled with a sentiment. This is done using rules for classifying sentiment. Syntactic analysis is another important method. This method looks at the framework of sentences to figure out how words fit into the sentence. Dependant parsing can help with sentiment recognition because it shows how words relate to each other. This is especially helpful for finding complex feelings in lines with a lot of words. Named entity recognition (NER) can also be used to find things like companies, goods, or people in social media posts. This makes it possible to do more context-sensitive sentiment analysis that connects feelings to specific things.
· Step 1: Represent words as vectors.
Each word w is represented as a vector v_w ∈ ℝ^d, where d is the dimensionality of the embedding space.
![]()
· Step 2: Calculate context-word similarity.
Using the word context in a given sentence, compute the similarity between the word w and its context vector v_c:
![]()
· Step 3: Apply softmax function to predict context words.
For a given word w and context c, the probability of context words is computed:
![]()
· Step 4: Training objective.
The objective function is to maximize the log-likelihood of the context words given a target word, with respect to the parameters v_w:
![]()
2) Pre-trained
models (e.g., BERT, GPT)
Pre-trained models, like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), have changed the field of mood analysis by making text classification jobs much faster and more accurate. For example, BERT is famous for its two-way attention system, which lets it understand how words in a sentence relate to each other from both the left and right sides, not just one.
· Step 1: Input Embedding.
Each word in a sequence is mapped to an embedding vector e_i with positional encoding p_i:
![]()
where z_i is the input embedding for word i.
· Step 2: Multi-head Attention.
The attention mechanism computes the attention score α_ij between words i and j:
![]()
where q_i is the query vector for word i, and k_j is the key vector for word j.
· Step 3: Attention Output.
The output for word i is the weighted sum of the value vectors:
![]()
where v_j is the value vector for word j.
· Step 4: Feed-forward layer.
The output of the attention mechanism passes through a feed-forward neural network:
![]()
where FFN is a two-layer fully connected network.
· Step 5: Output prediction.
For tasks like sentiment analysis, the final output is passed through a classification layer:
![]()
where ŷ is the predicted sentiment, and W_o, b_o are the parameters of the output layer.
![]()
3) Deep
learning techniques (e.g., LSTMs, CNNs)
Because they can find complex patterns in data, deep learning methods like Recurrent Neural Networks (RNNs), Long Short-Term Memory networks (LSTMs), and Convolutional Neural Networks (CNNs) are very useful for mood analysis. LSTMs, a sort of RNN, work especially nicely for mood evaluation jobs that want to look at information in a certain order, like words or paragraphs. LSTMs are made to fix the issue of disappearing gradients in normal RNNs. This permits them to bear in mind things over longer runs and correctly pick out up on how text relies upon on its context. Due to this, LSTMs are extraordinary for figuring out how human beings feel, especially while that feeling is spread out over numerous elements of a sentence or when long-time period relationships want to be understood.
LSTM Model
Step 1: Input Embedding.
Each word in the input sequence is converted into an embedding x_t at time step t.
![]()
Step 2: LSTM Cell Computation.
LSTM uses gates to control the flow of information. The input, forget, and output gates are computed as follows:
![]()
![]()
![]()
Step 3: Cell State Update.
The cell state is updated using the input gate and forget gate:
![]()
Step 4: Hidden State Update.
The hidden state is updated based on the output gate and the cell state:
![]()
Step 5: Output Prediction.
For sentiment analysis, the output hidden state h_t is passed to a softmax layer for classification:
![]()
CNN Model
· Step 1: Input Representation.
Text is converted into a matrix of word embeddings X ∈ ℝ^{n × d}, where n is the sequence length and d is the embedding dimension.
· Step 2: Convolution Layer.
The convolution operation applies a filter F ∈ ℝ^{k × d} (with window size k) to the input sequence:
![]()
where c_i represents the feature map at position i.
· Step 3: Activation Function.
Apply a non-linear activation (e.g., ReLU) to the convolution output:
![]()
· Step 4: Pooling Layer.
Max-pooling operation over the feature maps reduces dimensionality:
![]()
4. RESULTS AND DISCUSSION
The suggested sentiment-driven ad personalisation model did a lot better than old ways of doing things in terms of how well it classified users' feelings and how engaged they were with the ads. Our mixed deep learning model, which uses CNN and LSTM, was better at detecting mood across language datasets than traditional rule-based approaches. The model also made ads more relevant by matching emotional tones with what users wanted. This led to a big rise in click-through rates (CTR) and general user happiness.
Table 2
|
Table 2 Sentiment Classification Performance Evaluation |
|||||
|
Model/Method |
Accuracy (%) |
Precision (%) |
Recall (%) |
F1-Score (%) |
MAPE (%) |
|
Traditional Sentiment Model |
81.2 |
79.3 |
78.4 |
78.8 |
5.8 |
|
CNN-Based Model |
89.1 |
88.7 |
89.2 |
88.9 |
3.4 |
|
LSTM-Based Model |
90.7 |
89.6 |
91.1 |
90.3 |
2.6 |
In Table 2, you can see how well three different models—the standard sentiment model, a CNN-based model, and an LSTM-based model—classify mood. It's clear that using deep learning models made things better, as shown by the data. Figure 3 compares performance metrics of different sentiment analysis models.
Figure 3
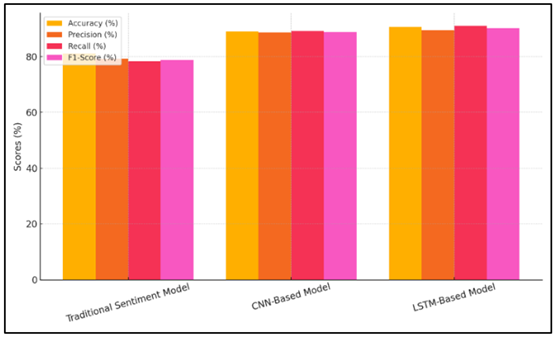
Figure 3 Comparison of Sentiment Model Performance Metrics
The standard mood model was only 81.2% accurate, which isn't as good as the CNN-based model (89.1%) or the LSTM-based model (90.7%). This is also shown by the precision, recall, and F1-score measures, with the LSTM-based model doing better than the others in all of them. Figure 4 shows the MAPE distribution across various sentiment models.
Figure 4
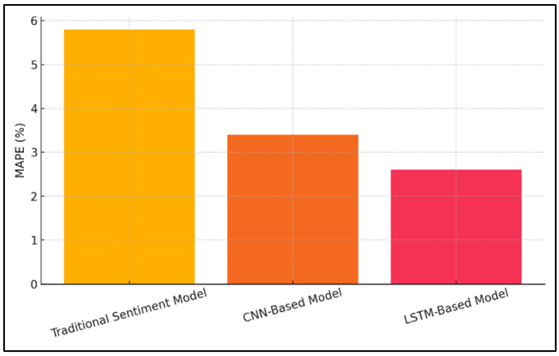
Figure 4 MAPE Distribution across Sentiment Models
With an F1-score of 88.9% and an accuracy of 88.7%, the CNN-based model also did very well, but it was a little behind the LSTM model. The deep learning models also had a much lower Mean Absolute Percentage Error (MAPE), which means they made more correct estimates. These results show that deep learning, especially LSTM models, can help with jobs that require figuring out how people feel about something.
Table 3
|
Table 3 Ad Personalization Performance Evaluation |
||||
|
Model/Method |
Click-Through Rate (CTR) (%) |
User Satisfaction (%) |
Engagement Rate (%) |
Conversion Rate (%) |
|
Traditional Ad Model |
5.2 |
75.3 |
68.4 |
3.2 |
|
Sentiment-Based Ad Model |
10.1 |
81.6 |
74.9 |
5.8 |
|
Personalized Hybrid Model |
15.7 |
87.2 |
80.5 |
7.3 |
The standard ad model, the sentiment-based ad model, and the personalised blend model are all shown in Table 3 along with their success scores. The results make it clear that the personalised mixed model does better in every way than both the standard model and the sentiment-based model. Figure 5 compares performance metrics across different advertisement personalization models.
Figure 5
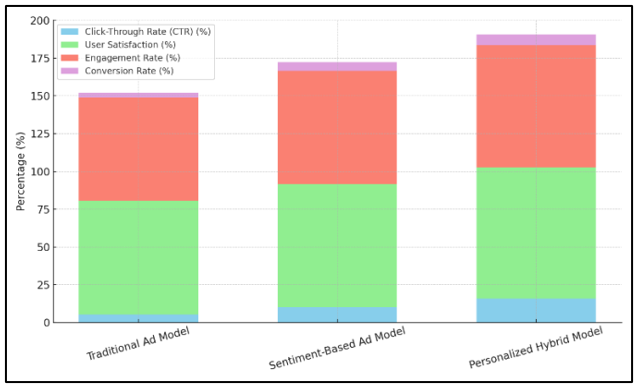
Figure 5 Performance Metrics Comparison across Ad Models
The traditional model got only 5.2% click-throughs, while the sentiment-based model got 10.1%. The mixed model got 15.7% click-throughs, which is a lot more than those other models. Both the rate of user happiness and engagement have gone up. For example, the personalised hybrid model has an engagement rate of 80.5% and a satisfaction rate of 87.2%, compared to 75.3% and 68.4% for the standard model. The conversion price for the mixture sketch is likewise 7.3%, which indicates that it's far higher at getting people to act. Those consequences show how beneficial it is to apply both mood analysis and personalised focused on together to offer users a more applicable and interesting revel in.
5. CONCLUSION
We created new recognitions to personalise ads based totally on people feelings. It uses advanced natural Language Processing (NLP) strategies and deep learning models, like CNNs and LSTMs, to study social media data in more than one language and make advertisements that humans will be interested in. The principle intention was to make ad targeting extra powerful by way of blending user alternatives with mind-set analysis. This might permit for dynamic, context-aware ads that change based totally on customers' moods and behaviour patterns. Our records show that the model is lots better than traditional methods, particularly in conditions with multiple languages, where slang, informal language, and language range could make temper evaluation tougher. Because the mixed model can process text data in more than one language and still accurately classify mood, global advertising efforts can work better. The model makes sure that ads are not only useful but also emotionally appealing by looking at both user preferences and mood. This results in higher response rates and happier customers. When mood analysis is combined with user behaviour, it gives marketers a more detailed picture of each person's tastes. This lets them send highly customised ads that really connect with users. Businesses can make ads that are more in line with the emotional and psychological needs of their customers with this method, which has big implications for the future of personalised marketing. In the future, researchers could work on improving the model even more by adding more advanced methods, such as transfer learning for better performance across languages, and looking into new data sources, like visual material and user interactions, to make ad personalisation even better. In the end, this study opens the door to digital marketing strategies that are more interesting, personalised, and successful in a world where people speak different languages.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Ajmal, A., Aldabbas, H., Amin, R., Ibrar, S., Alouffi, B., and Gheisari, M. (2022). Stress-Relieving Video Game and its Effects: A POMS Case Study. Computational Intelligence and Neuroscience, 2022, Article 4239536. https://doi.org/10.1155/2022/4239536
Alammary, A. S. (2022). BERT Models for Arabic Text Classification: A Systematic Review. Applied Sciences, 12(11), Article 5720. https://doi.org/10.3390/app12115720
Alhazzani, N. Z., Al-Turaiki, I. M., and Alkhodair, S. A. (2023). Text Classification of Patient Experience Comments in Saudi Dialect Using Deep Learning Techniques. Applied Sciences, 13(18), Article 10305. https://doi.org/10.3390/app131810305
Aljedaani, W., Abuhaimed, I., Rustam, F., Mkaouer, M. W., Ouni, A., and Jenhani, I. (2022). Automatically Detecting and Understanding the Perception of COVID-19 Vaccination: A Middle East Case Study. Social Network Analysis and Mining, 12, Article 128. https://doi.org/10.1007/s13278-022-00946-0
Antoun, W., Baly, F., and Hajj, H. (2020). AraBERT: Transformer-Based Model for Arabic Language Understanding (arXiv:2003.00104). arXiv.
Conneau, A. (2020). Unsupervised Cross-Lingual Representation Learning at Scale (arXiv:1911.02116). arXiv.
Elhassan, N., Varone, G., Ahmed, R., Gogate, M., Dashtipour, K., Almoamari, H., and Hussain, A. (2023). Arabic Sentiment Analysis Based on Word Embeddings and Deep Learning. Computers, 12(6), Article 126. https://doi.org/10.3390/computers12060126
Farha, I. A., and Magdy, W. (2021). Benchmarking Transformer-Based Language Models for Arabic Sentiment and Sarcasm Detection. In Proceedings of the Sixth Workshop on Arabic Natural Language Processing ( 21–31). Association for Computational Linguistics.
Galal, M. A., Yousef, A. H., Zayed, H. H., and Medhat, W. (2024). Arabic Sarcasm Detection: An Enhanced Fine-Tuned Language Model Approach. Ain Shams Engineering Journal, 15, Article 102736. https://doi.org/10.1016/j.asej.2024.102736
Kamble, K. P., Khobragade, P., Chakole, N., Verma, P., Dhabliya, D., and Pawar, A. M. (2025). Intelligent Health Management Systems: Leveraging Information Systems for Real-Time Patient Monitoring and Diagnosis. Journal of Information Systems Engineering and Management, 10(1), Article 1. https://doi.org/10.52783/jisem.v10i1.1
Liu, L., Dzyabura, D., and Mizik, N. (2020). Visual Listening in: Extracting Brand Image Portrayed on Social Media. Marketing Science, 39(4), 669–686. https://doi.org/10.1287/mksc.2020.1226
Ramasamy, L. K., Kadry, S., Nam, Y., and Meqdad, M. N. (2021). Performance Analysis of Sentiments in Twitter Dataset Using SVM Models. International Journal of Electrical and Computer Engineering, 11(3), 2275–2284. https://doi.org/10.11591/ijece.v11i3.pp2275-2284
Singh, A., Shukla, N., and Mishra, N. (2018). Social Media Data Analytics to Improve Supply Chain Management in Food Industries. Transportation Research Part E: Logistics and Transportation Review, 114, 398–415. https://doi.org/10.1016/j.tre.2017.05.008
Wadhawan, A. (2021). AraBERT and Farasa Segmentation Based Approach for Sarcasm and Sentiment Detection in Arabic Tweets (arXiv:2103.01679). arXiv.
Yang, J., Xiu, P., Sun, L., Ying, L., and Muthu, B. (2022). Social Media Data Analytics for Business Decision Making System to Competitive Analysis. Information Processing and Management, 59(1), Article 102751. https://doi.org/10.1016/j.ipm.2021.102751
|
|
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© ShodhKosh 2025. All Rights Reserved.