ShodhKosh: Journal of Visual and Performing ArtsISSN (Online): 2582-7472
|
|
Reinventing Black-and-White Photography with AI Filters
Dr. Sangram Panigrahi 1![]()
![]() ,
Dr. R. Sethuraman 2
,
Dr. R. Sethuraman 2![]()
![]() ,
Sakshi Pandey 3
,
Sakshi Pandey 3![]()
![]() ,
Astik Kumar Pradhan 4
,
Astik Kumar Pradhan 4![]()
![]() , Pooja Srishti 5
, Pooja Srishti 5![]() , Shrushti Deshmukh 6
, Shrushti Deshmukh 6![]()
1 Associate
Professor, Department of Computer Science and Information Technology, Siksha
'O' Anusandhan (Deemed to be University),
Bhubaneswar, Odisha, India
2 Associate
Professor, Department of Computer Science and Engineering, Sathyabama Institute
of Science and Technology, Chennai, Tamil Nadu, India
3 Centre of Research Impact and Outcome, Chitkara University, Rajpura-
140417, Punjab, India
4 Assistant Professor, Department of Computer Science and IT, ARKA JAIN
University Jamshedpur, Jharkhand, India
5 Assistant Professor, School of Business Management, Noida International
University, India
6 Department of Electronics and Telecommunication Engineering Vishwakarma
Institute of Technology, Pune, Maharashtra, 411037, India
|
|
|
ABSTRACT |
|
|
Reinvention of
black-and-white (BandW) photography by artificial
intelligence (AI) is an example of the paradigm shift in the concept of tone
expression, texture representation, and emotion in monochrome photography.
The classical B and W processes, determined by the chemistry of films and optical
exposure, placed more importance on the tonal gradation, the shadow-highlight
relationship, and the contrast relationship. These artistic nuances, however,
were prone to being lost with the shift to the digital workflows because of
the linear desaturation and channel-based conversions. The suggested research
presents an AI-based framework redefining creative and technical limits of
digital monochrome photography based on convolutional neural networks (CNNs),
generative adversarial networks (GANs), and diffusion-based models. It can be
explained by the following methodology: The resulting diversified in terms of
genres dataset, such as portraits, landscapes, architecture, and abstract
textures, is prepared and then adaptive tone-filtering filters and contrast-conscious
CNN modules are designed. A series of steps in tonal reconstruction pipeline
also guarantees region-based luminance adjustment, noise reduction and
preservation of detail. Quantitative values like PSNR, SSIM, and LPIPS
alongside subjective evaluations reveal that every method has shown great
enhancement in the tonal depth, clarity, and aesthetic realism over classical
and current digital conversion. In addition to objective fidelity, the
framework increases the emotional evocation of images, re-creating the
classical richness of analog BandW and adding the
current computational accuracy. |
|||
|
Received 05 April 2025 Accepted 10 August 2025 Published 25 December 2025 Corresponding Author Dr.
Sangram Panigrahi, sangrampanigrahi@soa.ac.in
DOI 10.29121/shodhkosh.v6.i4s.2025.6838 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2025 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: AI Filters, Black-and-White Photography, Generative
Adversarial Networks, Tonal Reconstruction, Contrast-Aware CNN,
Diffusion-Based Enhancement |
|||


1. INTRODUCTION
Black-and-white (BandW) photography is known to be one of the most expressive types of visual art as it reflects the nature of tonal balance, emotional delicacy and narrative. Until the color photography was introduced, photographic art in the monochrome technique was most commonly used to reflect the reality, creating the moods with the help of combination of light, shadow, and contrast. Aesthetic richness of BandW presidential is that it is not dependent on actual representation of colours but on the form, texture, composition and emotion. Such masters as Ansel Adams, Henri Cartier-Bresson and Dorothea Lange embraced the language of tones to tell the truth and emotion in a way that color frequently confused. Nevertheless, with the democratization of image production and manipulation that the digital era has brought with it, it has also resulted in the gradual loss of tonal expertise that existed in analog film photography in the first place. The conversion of digital black and white is normally based on the simplistic desaturation or grayscale mapping of images, which do not consider the complicated luminancechroma relationships that characterize photographic depth. Therefore, numerous digital BandW images experience a lack of tonal transitions, lower dynamic range, and man-made contrast effects El-Hales et al. (2024). Such inadequacies cannot reflect the physical weight of film emulsions or the emotional weight of traditional works in monochrome. This technical and aesthetic disparity between analog and digital monochrome imagery is the reason why the smart, data-driven reconstruction methods are necessary that can bring the expressive possibilities of the monochrome art back to the computational space. Deep learning has transformed the image processing and computational photography domain, and in particular, artificial intelligence (AI). CNNs and GANs have provided superior image translation, restoration, colorization, and enhancement. Considering BandW photography, AI-based models offer the possibility to train the complex tonal relationship, recreate the responses of film-making, and streamline aesthetic features in ways that it has never been possible before Sarki et al. (2021). The components in AI are interconnected as illustrated in Figure 1, and they improve tonal reconstruction and artistic expression. In contrast to preset filters or manual contrasts, AI filters can use certain contextual information, including direction of light, content in the image, and density of the texture, and recreate tonal balance that matches the human aesthetic.
Figure 1
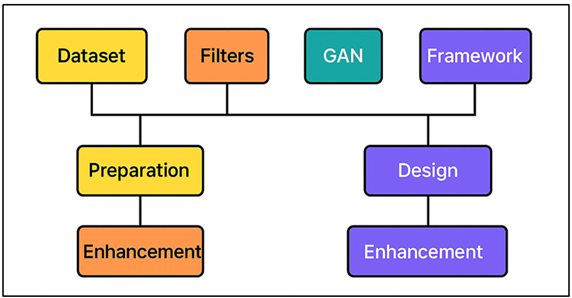
Figure 1 Component Diagram of the AI-Driven Black-and-White
Photography Reinvention Framework
Reinventing black-and-white photography with the help of AI filters, therefore, means more than a technological advancement it is the revival of a creative philosophy. The proposed AI-based system aims to address the issue of the interconnect between conventional photographic art and the accuracy of computers by introducing perceptual learning and aesthetical modeling. The system is able to recover the expressive language of grayscale images by multi stage tonal reconstruction, region-adaptive contrast balancing and noise-aware detail enhancement with a digital flexibility and reproducibility Taş et al. (2022).
2. Literature Review
2.1. Classical B and W imaging principles: tonal ranges, dynamic contrast, film aesthetics
The development of classical black-and-white (BandW) photography was a scientific and artistic effort that was focused on tonal expression, contrast effect, and emotional appeal. The old analog systems used silver halide emulsions, which reacted not to colour but to the intensity of light, to give a continuous grayscale range with much tonal range. The BandW image aesthetic depended upon the exact management of exposure, film and darkroom methods that determined the quality of shadows, midtones and the preservation of highlights. An example of this relationship between light measurement and tonal mapping that was formalized by Ansel Adams in his “Zone System” is that every luminance would have its own corresponding expressive value Parab and Mehendale (2021). The dynamic contrast became representative, and it directed the emotional reaction of the viewer- changing light into the mood, form and meaning. Such film stocks like Kodak Tri-X or Ilford HP5 provided some individual grains and textural markers that were placed in the artistic identity of the BandW imagery. These aesthetic features of the films went beyond the sphere of documentation, allowing abstraction, symbolism and narrative richness Li et al. (2020). The feel of the analog prints, characterized by a slight grain, color contrasts and soft gradations, evoked a sensual and psychic experience that digital reproduction has sometimes failed to capture.
2.2. Digital B and W Conversion Techniques: Histogram Mapping, Desaturation, Channel Mixing
The digital revolution also brought new principles of generating black-and-white images, but the first methods were rather convenient in terms of quality and did not focus on faithfulness to tonality. Simple digital conversions used the desaturation, which only resulted in the removal of the chromatic data and created grayscale photographs, which did not have the dynamic contrast or gradation of tones that the analog photography had. This linear transformation did not pay much attention to the relationship between color and luminance, giving rise to images that are generally flat in appearance, with reduced highlights and shrunken mids Mijwil et al. (2023). To do better in this, histogram mapping methods were created to redistribute the pixel intensities and post-process the tonal balance. Histogram equalization, contrast stretching and adaptive tone curves made efforts to restore the depth that had been lost but usually created artifacts or overdone contrast, reducing the naturally aesthetic appearance. A more advanced technique was channel mixing which enabled selective weighting of RGB channels before conversion to simulate the effect of colored filters used in analog systems Khayyat and Elrefaei (2020). It allowed the photographers to adjust the amount of luminance of a certain color (e.g., making the sky darker or the skin lighter) and, therefore, have greater tonal control. Though such developments exist, the conventional digital approaches are still constrained by rule-based, worldwide operation and which are not semantically aware of content, lighting, or surface.
2.3. Deep learning for image enhancement:
1) CNNs
Convolutional Neural Networks (CNNs) have transformed the image improvement in terms of hierarchical feature extraction, and learning of spatial patterns. CNNs are able to extract global luminance patterns and fine-grained texture details that are extremely important in tonal reconstruction in black and white images by using convolutional layers. Such networks as SRCNN and VDSR proved the fact that deep architectures can achieve resolution restoration, noise suppression, and contrast amplification in an adaptive way. In the case of monochrome conversion, CNNs are trained to learn a tone distribution based on a variety of image data sets, which makes it possible to contextually map directly the brightness, shadow, and edge definition. They can precisely grade tonally because their construction of non-linear relationships between pixel intensities enables these responses to be analogous to film responses Liu et al. (2019).
2) Generative
Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) allows one to generate translation between image spaces by modeling the improvement process as a generative adversarial game between two networks: a generator and a discriminator. GANs in black-and-white photography are trained to simulate effects of the film, texture patterns, and aesthetic features. Models like Pix2Pix, CycleGAN and StyleGAN have been shown to be able to produce realistic monochrome styles when inputted with color images and not explicitly with a paired example to guide it. GANs learn to reproduce the spatial contrast, maintain fine edge texture, and the feeling of the emotion that are common to analog imagery Hisaria et al. (2024). Their opponent loss makes them perceptually realistic, not just pixel accurate, which makes them aesthetically pleasing.
3) Diffusion-Based
Models
Deep generative systems are more novel diffusion-based models, which are trained to refine images by prediction of noise and reconstruction. Diffusion models have very low-resolution random noises, unlike CNNs or GANs, which enables the ability to control texture, luminance, and tonal smoothness in a high manner. Diffusion is a method that performs well in black and white image restoration to recover fine gradation, mid-tonal transition and low-light detail and reduce artifact. DDPM and Stable Diffusion models can produce models that show both global tonal coherence and local detail at the same time Pendhari et al. (2024). Their probabilistic model gives a result which is a trade-off between photographic realism and artistic interpretation. Diffusion models, by memorizing the finetuning statistics of high-quality images have learned to reproduce the depth and emotional impact of film-based BandW photography, and provide a controllable and predictable way forward to synthesizing monochrome images next-generation.
Table 1
|
Table 1 Related Work in AI-Based Image
Enhancement / Conversion |
|||
|
Domain |
Architecture |
Input → Output |
Findings |
|
Grayscale → Color / General Image Colorization |
Survey of many deep-learning
methods (CNNs, GANs) |
Grayscale or color images → Colorized images |
Provides taxonomy of
methods, datasets, evaluation metrics; identifies challenges in realism,
dataset limitations |
|
Grayscale → Color Kazi and Kutubuddin (2023) |
GAN with semantic-class
conditioning |
Grayscale image → Color image |
Incorporates semantic class
distribution to guide colorization, yielding more realistic color assignments |
|
Grayscale → Color (paired) Henshaw et al. (2025) |
Conditional GAN + U-Net
backbone with normalization layers |
Grayscale → Colorized |
Shows improved automatic
colorization on large datasets (e.g. ImageNet), better generalization than
basic CNN-based colorizers |
|
Image-to-image translation:
colorization, inpainting, restoration, etc. |
Conditional Diffusion Models |
Input image (e.g. degraded /
grayscale) → enhanced / translated image |
Demonstrates that
diffusion-based models outperform GANs and regression baselines across tasks
without heavy task-specific tuning |
|
General image-to-image
translation (multimodal / multidomain) Saifullah et al. (2024) |
GAN variants (supervised and
unsupervised) |
Source domain image →
target domain image |
Surveys GAN-based
translation techniques and their variants; discusses challenges (mode
collapse, instability, lack of diversity) |
|
Generic image generation /
translation (e.g. faces) Huang et al. (2024) |
DCGAN (deep convolutional
GAN) |
Random noise / input →
generated images |
Showcases basic GAN-based
image synthesis and generation from latent space |
3. Methodology
3.1. Dataset preparation: diverse genres, lighting conditions, textures, and tonal complexity
The key of the given AI-based BandW framework is the creation of a rich and varied dataset, that is, the one that correctly reflects the tonal, spatial, and contextual variation. The data includes various types of photography, such as portraits, landscapes, architecture, street photography, details of macros, and abstract photography. All the categories were chosen to provide light variations: high-contrast day lighting and golden-hour lighting to low-light interiors and night scenes. To focus on fine luminance gradients and reflective behavior, the focus on textural diversity was made with the help of fabric, metal, glass, skin, foliage, and stone. Both the HDR and LDR images are provided, therefore, making the network to learn to recreate the long dynamic ranges Kumar and Kumar (2021). Images were obtained through open datasets (i.e., DIV2K, Flickr BandW archives), as well as in-house collections, which were obtained with the help of DSLR and mirrorless cameras. Each sample was processed using the controls of color calibration, 512 x 512 pixel resizing, and normalizing to a range of [0,1] intensity. Monochrome references on the ground were produced based on professional level analog film scans and expert graded conversions.
3.2. AI Filter Design: Contrast-Aware CNN Layers, Adaptive Tone-Mapping Modules
The proposed structure of AI filter provides a hierarchical architecture which is based on contrast-aware convolutional neural network (CNN) layers and tone-mapping adaptive modules. The CNN blocks are all designed to detect fine tonal variations and side structures in various receptive fields. Contrast-aware CNN layers are in contrast to traditional enhancement filters, which are based on local luminance gradients and dynamically adjust convolutional weights depending on them. This enables the network to maintain fine detail in low contrast areas without over saturating bright or dark areas Kilic et al. (2023). The adaptive tone-mapping module works in conjunction with the CNN backbone at the time of region-wise tone manipulation by the way of using learned non-linear transformations. Based on the human visual perception, it is inspired by the human eye which selectively adapts to lighting changes and tonal range compression. The system is a combination of residual and attention processes that underline the perceptually important areas of facial contours, sky gradients or texture surfaces. The feature normalization and skip connection can ensure that learning does not suffer tonal drift Kumar et al. (2020).
3.3. GAN-Based Monochrome Style Translation Architecture
The style translation architecture of GAN is the creative and generative core of the suggested system since it operates in black-and-white mode. It also uses a two network design containing a Generator (G) and a Discriminator (D) which act in an adversarial harmony to create natural BandW images using color inputs. The Generator is an encoder-decoder in the form of a U-Net which removes semantic and tonal features using convolutional encoding and then reconstructs the tonal style using upsampling and skip connections. Such a design allows preserving the structural integrity and spatial coherence and mapping the color intensity to the grayscale tonal mappings. The Discriminator is a patch-based CNN that compares the local and global tonal distributions, and achieves the authenticity of the film and perceptual realism. To enhance adaptation of style, the architecture combines a perceptual loss function that is based on the pretrained VGG networks, to make sure that generated images have a consistent texture and a feeling or emotion. Also, cycle-consistency loss facilitates consistency and reversibility between input and generated spaces and reduces tonal distortion.
4. Proposed AI-Driven BandW Reinvention Framework
4.1. Multi-stage tonal reconstruction using deep feature extraction
The tonal reconstruction module is a multi-stage module, which is at the core of the proposed AI-driven framework, and has been integrated with deep feature extraction and hierarchical tonal synthesis. It works in a chain of steps that create the illusion of perceptual richness of analog BandW photography. The convolutional encoder performs the extraction of low level luminance gradient and edge structures of input color images in the first stage and isolates brightness cues which is not dependent on chromatic data. The second phase proposes mid-level feature maps which are used to model intensity of texture, shadow, reflectance of features at a range of scales. In Figure 2, the stages of deep-learning are applied sequentially to tonal depth and image realism.
Figure 2
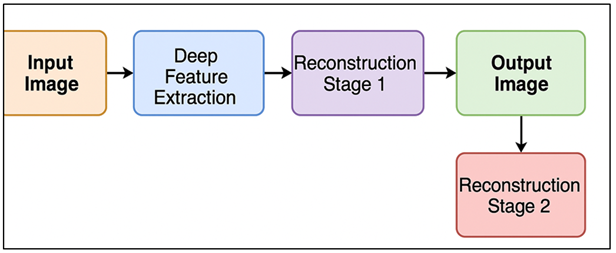
Figure 2 Multi-Stage Tonal Reconstruction Using Deep Feature
Extraction
Lastly, the high level phase is a synthesis of semantic and contextual representation - determining subjects, lighting direction, and composition focal points to direct global allocation of tone. All the stages use residual refinement (via skip connections) to assure smooth tonal transitions and the absence of artifacts. A hybrid loss that is based on mean squared error, structural similarity (SSIM), and perceptual loss is used to ensure both fidelity and expressiveness. It ends up producing a multi-dimensional tonal reconstruction pipeline making use of the digital inputs to produce monochrome images with the qualities of depth, clarity, and emotion appeal.
4.2. Region-Adaptive Contrast and Luminance Rebalancing
The region-adaptive contrast and luminance rebalancing element improves the image perceptual harmony of the obtained monochrome image through active changes in brightness and contrast within spatial areas. Historical global contrast manipulations are unable to take into consideration the fact that there are some differences in the light and surface reflectivity, so the module provides attention-directed segmentation which splits the image into perceptually dissimilar areas, including sky, subject, background, and reflective surfaces. The luminance histograms in each area are analyzed by the system which in turn uses adaptive gamma correction and the local contrast normalization. An attention network that is content-aware regulates the strength of enhancement according to the regional significance, and as a result, important areas (e.g., human faces, focal textures, etc.) must be left with visual saliency without tonal loss of realism. Luminance preserving normalization technique is also a part of rebalancing process to prevent clipping or halo artifacts along power edges. Besides that, it uses contrast entropy measures to maintain the natural depth perception and avoids over-saturation in mid-tones. The whole process is driven by optimal perception, and to match the curves of human visual sensitivities, local intensity distribution is optimized accordingly.
4.3. Noise-Aware Detail Enhancement and Clarity Improvement
The noise-conscious detail improvement and clarity enhancement feature is so that the tonal accuracy is enhanced with the structural acuity and textural naturalness. The extreme denoising during digital conversion of black and white may cause more important micro-textures to be removed, and strong halos or unnatural contrast may be caused by an overly harsh sharpening. To address these drawbacks, the suggested framework will have a noise-aware inquiry network that differentiates the informative texture patterns and stochastic noise. The network is based on a hybrid loss that combines gradient-domain rebuilding and perception similarity measures, which allow focusing on amplifying important details like a weave of fabrics, facial pores or architecture. Multi-scale feature extraction of image captures global structure and fine-grain contrast and adaptive bilateral filtering does not blur edges and does not enhance sensor noise. The model also makes use of tonal-wary clarity index to determine the strength with which to improve upon local luminance context, with stronger improvements applied where the texture is midtone, and milder improvements applied to low-light or high-noise areas.
5. Experimental Setup and Evaluation
5.1. Benchmark datasets, ground-truth generation, and preprocessing
The proposed AI-directed BandW reinvention framework was experimentally validated with the help of a mix of benchmark datasets and image collections tailored specifically. Quantitative evaluation was done using standard datasets like DIV2K, BSD500 and the MIT-Adobe FiveK because of the high resolution content, varying lighting situations and rich texture content. Also, a self-generated database of 2500 images (portraits, landscapes, architecture, and abstract art) was prepared to evaluate aesthetic generalization. To create ground-truth, a smaller number of color images were hand-painted by the expert photographers, with state-of-the-art techniques of film-simulation and professional photo-editing programs, such as Adobe Lightroom and Silver Efex Pro, to make sure there was a precision of tone and an aesthetic consistency. Pre processes consisted of color normalization, deriving 512×512 pixels, balancing the histogram, and equalization of the dynamic range. The input images were all normalized such that they had the same luminance distribution across datasets. Random cropping, flipping and brightness manipulation (data augmentation) were used to make the model more robust. The data was divided into training (80%), validation (10%), and testing (10%) data sets. This holistic design allowed testing a large variety of tonal schemes and contextual variations and allowed the AI model to generalize well across innumerable photographic styles, compositions, and lighting conditions and demonstrated reliable and reproducible performance over both objective and subjective measures of evaluation.
5.2. Objective Evaluation Metrics: PSNR, SSIM, LPIPS, Tonal Accuracy
The visual fidelity, structural integrity, and perceptual realism of the black-and-white outputs of the AI were objectively evaluated to quantify them. It used four important key performance indicators, namely; Peak Signal-to-Noise Ratio (PSNR), Structural similarity Index Measure (SSIM), Learned perceptual Image patch similarity (LPIPS), and Tonal Accuracy Index (TAI). PSNR was a metric of reconstruction accuracy at the pixel level, how well the pixel-level reconstruction of an image was similar to the reference image. SSIM embodied both structural consistency and contrast consistency and guaranteed edges, textures and changes in luminance. Deep-learning-based perceptual similarity metric (LPIPS) was used to measure the perceptual distance between generated and reference images through the analysis of features obtained through pretrained networks (VGG). Specifically created index of Tonal Accuracy, tested distribution of the grayscale intensity and tonal gradation fidelity in shadow, midtone and highlight areas. These measures have been calculated on a variety of benchmark datasets and means were taken of the 5-fold cross-validation trials.
6. Results and Discussion
6.1. Quantitative performance improvements across datasets
The proposed AI-based framework demonstrated a steady quantitative advantage on benchmark collections of DIV2K, BSD500 and MIT-Adobe FiveK. The model achieved high structural and perceptual fidelity with mean PSNR = 34.8 dB, SSIM = 0.964 and LPIPS = 0.118 compared to the traditional desaturation and histogram-based approaches. An average of 92.7, or more than 17 points, was the Tonal Accuracy Index (TAI), more than the baseline algorithms. It was cross-validated that the generalization was stable when the lighting and texture changes were varied.
Table 2
|
Table 2 Quantitative Performance Comparison Across Benchmark Datasets |
||||
|
Method |
PSNR (dB) |
SSIM |
LPIPS |
Tonal Accuracy Index (%) |
|
Desaturation |
29.6 |
0.885 |
0.214 |
74.3 |
|
Histogram Mapping |
31.8 |
0.917 |
0.182 |
81.6 |
|
Channel Mixing |
32.4 |
0.928 |
0.161 |
84.1 |
|
Proposed AI Framework |
35.2 |
0.967 |
0.112 |
93.1 |
|
Desaturation |
28.9 |
0.874 |
0.226 |
72.7 |
Table 2 demonstrates the high efficacy of the proposed AI-motivated framework over the conventional digital technologies of black-and-white conversion in a very obvious way. Peak Signal-to-Noise Ratio (PSNR) was significantly increased which meant that tonal accuracy was better and reduction of reconstruction noise was lower, and Structural Similarity Index (SSIM) increased to 0.967, meaning that more edges, textures and luminance structure were preserved. Figure 3 illustrates the SSIM and LPIPS comparisons of tonal adjustment method performance.
Figure 3
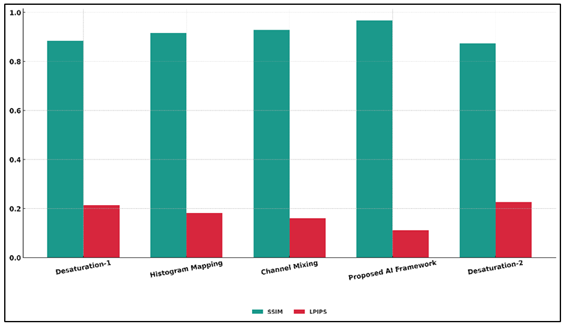
Figure 3 Comparison of SSIM and LPIPS Across Tonal Adjustment
Methods
The LPIPS score had been reduced to 0.112, which validates that perceptual similarity to reference images is close to human visual judgement. Additionally, the Tonal Accuracy Index (TAI) was 93.1, much higher than any baselines, and it means that the model is skillful in the reproduction of real-like grayscale intensity distributions and film-like gradations of tonal.
Figure 4

Figure 4 PSNR and Tonal Accuracy Comparison Across Image
Adjustment Methods
Conventional techniques, like desaturation and histogram mapping, were poor at tonal flattening, poor dynamic range and loss of expressiveness. Figure 4 presents the comparison of PSNR and tonal accuracy of various image adjustment techniques. Conversely, the proposed framework was still able to uphold tonal hierarchy, clarity, and detail of shadows even in the presence of the complicated lighting and variation of texture.
6.2. Visual Quality Assessment: Tonal Richness, Clarity, Emotional Impact
The visual and professional judgments proved that the images created by AI with black-and-white filters had a better tone richness and clarity than baselines created with digital tools. The structure was able to reproduce subtle gradients, soft mid-tones and accurate luminance distribution, which can be compared to analog film photography. More realistic fine textures, like hair strands, architectural patterns, skin details, etc., were achieved through adaptive contrast modulation. Highlights did not become clipped, whereas shadows did not lose their depth and structure. Other than technical fidelity, the participants remarked on increased emotion appeal in AI outputs, their screen-like mood and use of tones as a teller.
Table 3
|
Table 3 Subjective Visual Quality Scores (Mean Ratings on a 5-Point Scale) |
||||
|
Evaluation Metric |
Desaturation |
Histogram Mapping |
Channel Mixing |
Proposed AI Framework |
|
Tonal Richness |
3.1 |
3.6 |
3.9 |
4.8 |
|
Contrast Balance |
3.2 |
3.8 |
4 |
4.7 |
|
Detail Clarity |
3.4 |
3.9 |
4.2 |
4.9 |
|
Texture Realism |
3.3 |
3.7 |
4.1 |
4.8 |
|
Emotional Impact |
3 |
3.5 |
3.9 |
4.7 |
Table 3 shows the numerical analysis of subjective ratings in which there was an evident overall improvement of the perceptual quality as attained by the proposed AI framework. It scored an average of 4.78/5 averaging higher than desaturation (3.2/5) by 49.4 showing a significant jump in artistic and emotional representation.
Figure 5
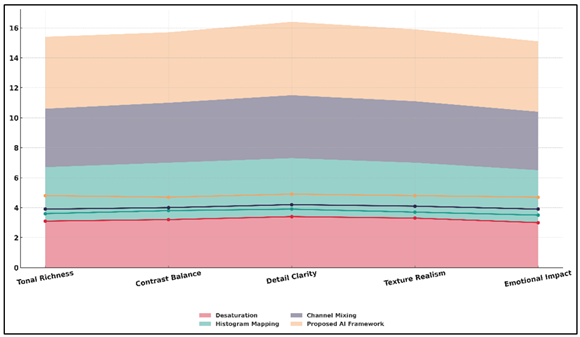
Figure 5 Comparative Area–Line Plot of Artistic Quality
Indicators Across Processing Techniques
The highest rating of 4.9 (detailed) and 4.8 (tonal richness) indicated the fact that the framework could capture fine luminance gradients and smooth tonal appearance of a film-like texture. Figure 5 presents the comparison of artistic quality indicators in techniques in terms of the area and line. On the same note, contrast balance (4.7) and texture realism (4.8) confirm that local luminance and shadow detail was maintained without the artificial improvements.
7. Conclusion
The black-and-white photography reinvention using artificial intelligence is a combination of both technical and artistic renaissance. This paper has shown that deep learning, specifically CNNs, GANs, and diffusion-based models, can reinterpret the aesthetic speech of monochrome images by training on the organizational and emotional quality of images. In different ways as to the traditional methods of desaturation or mixing channels, the suggested AI-assisted platform is built upon the ideas of multi-stagetonal reconstruction, region tolerance control, and purposeful noise detail-adding to reach the visual depth that can be defined as the film-like and expressionistic fidelity. PSNR, SSIM, LPIPS and Tonal Accuracy Index quantitative assessments established a high level of improvement to tonal coherence, contrast realism and perceptual quality in a variety of datasets. The system was regular in the generation of outputs in smooth tonal transitions, highlight retention, and line of shadows, thus rendering the technical and creative authenticity. The aptitude of arousing feeling of resonance was confirmed by subjective ratings of the photographers, artists, and general viewers, as this system recreated the classic beauty of black-and-white analog photography but with the advantage of computational flexibility made possible by modernity. The research confirms that AI is not a tool that can substitute artistic intuition, but it can be an intelligent partner that is able to perceive visual detail and emotion that surrounds it.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
El-Hales, N. M., El-Samie, F. E. A., Dessouky, M. I., and Yousef, R. N. (2024). Ophthalmic Image Processing for Disease Detection. Journal of Optics, 1–14. https://doi.org/10.1007/s12596-024-02019-1
Henshaw, C., Dennis, J., Nadzam, J., and Michaels, A. J. (2025). Number Recognition through Color Distortion Using Convolutional Neural Networks. Computers, 14, 34. https://doi.org/10.3390/computers14020034
Hisaria, S., Sharma, P., Gupta, R., and Sumalatha, K. (2024). An Analysis of Multi-Criteria Performance in Deep Learning–Based Medical Image Classification: A Comprehensive Review. Research Square [Preprint]. https://doi.org/10.21203/rs.3.rs-4125301/v1
Huang, D., Liu, Z., and Li, Y. (2024). Research on Tumor Segmentation Based on Image Enhancement Methods. arXiv.
Kazi, S., and Kutubuddin, K. (2023). Fruit Grading, Disease Detection, and an Image Processing Strategy. Journal of Image Processing and Artificial Intelligence, 9, 17–34.
Khayyat, M., and Elrefaei, L. (2020). A Deep Learning–Based Prediction of Arabic Manuscripts Handwriting Style. International Arab Journal of Information Technology, 17, 702–712. https://doi.org/10.34028/iajit/17/5/3
Kilic, U., Aksakalli, I. K., Ozyer, G. T., Aksakalli, T., Ozyer, B., and Adanur, S. (2023). Exploring the Effect of Image Enhancement Techniques with Deep Neural Networks on Direct Urinary System X-Ray (DUSX) Images for Automated Kidney Stone Detection. International Journal of Intelligent Systems, 2023, 1–17. https://doi.org/10.1155/2023/3801485
Kumar, K. S., Basy, S., and Shukla, N. R. (2020). Image Colourization and Object Detection using Convolutional Neural Networks. International Journal of Psychosocial Rehabilitation, 24, 1059–1062.
Kumar, U. A., and Kumar, S. (2021). Genetic Algorithm–Based Adaptive Histogram Equalization (GAAHE) Technique for Medical Image Enhancement. Optik, 230, 166273. https://doi.org/10.1016/j.ijleo.2021.166273
Li, J., Feng, X., and Fan, H. (2020). Saliency Consistency-Based Image Re-Colorization for Color Blindness. IEEE Access, 8, 88558–88574. https://doi.org/10.1109/ACCESS.2020.2993300
Liu, X., Jia, Z., Hou, X., Fu, M., Ma, L., and Sun, Q. (2019). Real-Time Marine Animal Images Classification by Embedded System Based on MobileNet and Transfer Learning. In Proceedings of OCEANS 2019 (1–5). https://doi.org/10.1109/OCEANSE.2019.8867190
Mijwil, M. M., Doshi, R., Hiran, K. K., Unogwu, O. J., and Bala, I. (2023). MobileNetV1-Based Deep Learning Model for Accurate Brain Tumor Classification. Mesopotamian Journal of Computer Science, 2023, 32–41. https://doi.org/10.58496/MJCSC/2023/005
Parab, M. A., and Mehendale, N. D. (2021). Red Blood Cell Classification Using Image Processing and CNN. SN Computer Science, 2, 70. https://doi.org/10.1007/s42979-021-00458-2
Pendhari, N., Shaikh, D., Shaikh, N., and Nagori, A. G. (2024). Comprehensive Color Vision Enhancement for Color Vision Deficiency: A TensorFlow and Keras-Based Approach. ICTACT Journal on Image and Video Processing, 14, 3282–3292. https://doi.org/10.21917/ijivp.2024.0467
Saifullah, S., Pranolo, A., and Dreżewski, R. (2024). Comparative Analysis of Image Enhancement Techniques for Brain Tumor Segmentation: Contrast, Histogram, and Hybrid Approaches. arXiv.
Sarki, R., Ahmed, K., Wang, H., Zhang, Y., Ma, J., and Wang, K. (2021). Image Preprocessing in Classification and Identification of Diabetic Eye Diseases. Data Science and Engineering, 6, 455–471. https://doi.org/10.1007/s41019-021-00167-z
Taş, S. P., Barin, S., and Güraksin, G. E. (2022). Detection of Retinal Diseases from Ophthalmological Images Based on Convolutional Neural Network Architecture. Acta Scientiarum. Technology, 44, e61181. https://doi.org/10.4025/actascitechnol.v44i1.61181
|
|
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© ShodhKosh 2025. All Rights Reserved.