ShodhKosh: Journal of Visual and Performing ArtsISSN (Online): 2582-7472
|
|
Reinforcement Learning in Creative Skill Development
Madhur Taneja 1![]()
![]() ,
Harsh Tomer 2
,
Harsh Tomer 2![]()
![]() ,
Akhilesh Kumar Khan 3
,
Akhilesh Kumar Khan 3![]() , Sunil Thakur 4
, Sunil Thakur 4![]() , Manish Nagpal 5
, Manish Nagpal 5![]()
![]() ,
Dr. Anita Walia 6
,
Dr. Anita Walia 6![]()
![]() ,
Shailesh Kulkarni 7
,
Shailesh Kulkarni 7![]()
1 Centre
of Research Impact and Outcome, Chitkara University, Rajpura- 140417, Punjab,
India
2 Assistant
Professor, Department of Journalism and Mass Communication, Vivekananda Global
University, Jaipur, India
3 Lloyd Law College, Greater Noida, Uttar
Pradesh 201306, India
4 Professor, School of Engineering and Technology, Noida International
University, 203201, India
5 Chitkara Centre for Research and Development, Chitkara University,
Himachal Pradesh, Solan, 174103, India
6 Associate Professor, Department of Management Studies, JAIN
(Deemed-to-be University), Bengaluru, Karnataka, India
7 Department of E and TC Engineering Vishwakarma Institute of
Technology, Pune, Maharashtra, 411037, India.
|
|
|
ABSTRACT |
|
|
Reinforcement
Learning (RL) is a very effective computational model that has been used to
model adaptive decision-making but not exploited yet in advancing development
in creative skills. This paper explores the application of RL in developing
creativity in areas of visual art, music composition, design, and writing. We
can place RL as a natural process of directing agents to new and valuable
outcomes by theorizing creativity as a process that can be learned, and
improved through exploration, evaluation and refinement. The study
incorporates the knowledge in the areas of cognitive science, computational
creativity, and available applications of RL to develop a methodology
(environment simulation, creative dataset, and reward-based learning
algorithm) to achieve environment simulation. We have an RL-based creative
agent, which can interact with environment-specific domains via the feedback
loop and dynamically determined reward functions that encourage originality,
coherence and aesthetic or usability. The model structure focuses on
multi-modal input representation, hierarchical acquisition of policy and
adapting the reward modulation in order to stimulate cognitive diversity and
intentional exploration. Testing is based on quantitative measures of
creativity (novelty support, distributional distance, and statistical
surprise) and qualitative measures of creativity, as determined by human
subjects. Findings show that creative heuristics can be gradually learned by
the agents of RL and that more and more original artifacts can be produced by
the agents and that the agents update their strategies based on the
evaluative feedback. |
|||
|
Received 15 March 2025 Accepted 16 July 2025 Published 20 December 2025 Corresponding Author Madhur
Taneja, madhur.taneja.orp@chitkara.edu.in DOI 10.29121/shodhkosh.v6.i3s.2025.6791 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2025 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: Reinforcement Learning, Computational Creativity,
Creative Skill Development, Reward Modeling, Generative AI, Adaptive Learning |
|||


1. INTRODUCTION
1.1. Definition and Scope of Reinforcement Learning (RL)
Reinforcement Learning (RL) is a machine learning computational framework that allows an agent to acquire optimal behaviours by interacting with an environment, by means of feedback (rewards or penalties). In contrast to supervised learning, in which tasks are based on labeled data, or unstructured learning, in which learning tries to find patterns in unstructured data, RL focuses on the sequential decision-making process and the process of trial and error. A RL agent monitors its state, chooses an action guided by a policy, and gets a reward indicating utility of an action in respect to a long-term goal Liu and Rizzo (2021). In the course of repeated trials, the agent changes its estimates of values, and it modifies its policy to maximize its cumulative rewards. The field of RL is broadened beyond the more basic Markov decision processes (MDPs) to the more advanced partially observable systems, multi-agent systems, and continuous action space problems addressed by the deep reinforcement learning style. These are Q-learning, policy gradients, actor-critic models, and model-based RL that contribute to the better scalability and generalization of complex real-world tasks DeYoung and Krueger (2021). In addition to the classical uses of RL such as robotics, game-playing, and control systems the use of hierarchical structures, meta-learning and intrinsic motivation mechanisms have been introduced to facilitate exploration even in sparse-reward situations.
1.2. Understanding Creativity as a Learnable Process
The commonly held view of creativity as an innate human attribute is being challenged by modern studies of psychology, neuroscience, and computational modeling, which are increasingly describing creativity as a process that can be learned, refined and enhanced, and repeated. Creativity is the process of producing outputs that are innovative and useful in a particular context and this twofold requirement implies that creative capability does not only rest on spontaneous inspiration, but rather on systematized exploration, the incorporation of feedback, and refinement. Creative fluency is built cycle by cycle between trial, error and adaptation processes that are very similar to learning dynamics of reinforcement-driven behavior Ashton et al. (2020). The cognitive theories advance the idea that creativity is created through the interactions of divergent and convergent thinking, in which people consider a variety of unorthodox ways and select and develop promising ideas respectively. This tradeoff brings forth creativity as an act of directed exploration which is influenced by inner heuristics and external restrictions. Additionally, there is empirical evidence that with repeated exposure, practice and goal-guided experimentation, creative competence can improve tremendously over time Shakya et al. (2023). Creativity is even more learnable when it is seen through the prism of computation: original music, images or solutions can be trained through an algorithm that gets adapted to the parameters based on evaluative feedback. This implies that scaffolding creativity may be achieved using systematic feedback-based processes and not just chance.
1.3. The Need for AI-Driven Creative Skill Development
The increasing complexity and interdisciplinarity of the creative work of the present day have heightened the need and desire of instruments and models that improve human creativity and facilitate the formation of novel types of computational creative expression. With the growth in scale and the proliferation of creative industries (design, digital media, entertainment, advertising, and content creation) and an increased diversification of modes, people and organizations now face the need to have adaptive systems that facilitate ideation, experimentation and skill building Song et al. (2023).
Figure 1

Figure 1 Rationale for Implementing AI in Creative Skill
Enhancement
AI-based solutions have the potential to be a prolific answer, as they allow individuals to receive individual feedback, create a variety of options, and explore the creative opportunities in order. Figure 1 shows major reasons why AI is adopted in advancing the creative abilities. The conventional learning models do not have the potential to provide real time and contextualized instruction, which is prerequisite to the process of creative refinement achieved through iteration. The system based on Reinforcement Learning (RL) in particular may simulate the creativity as a sequence of decisions and allow the agent to learn the high-level strategies and the fine-grained methods of the creation of original and meaningful outputs Khalid et al. (2024). Such AI systems can also act as co-creative companions where they complement human capacity and not substitute the capacity by proposing alternatives, assessing the in-between outcomes, and promoting exploration beyond the normal human limits.
2. Related Work and Theoretical Background
2.1. Historical Development of RL in Cognitive and Behavioral Sciences
The history of Reinforcement Learning (RL) can be traced back to the original studies conducted in psychology and behavioral sciences, in which researchers tried to explain how organisms learn by interacting with the environment. The initial theories have been developed based on behaviorist models, specifically those introduced by Thorndike and Skinner who put forward the ideas of trial-and-error learning and operant conditioning Dong et al. (2021). This combination of theories highlighted that behavior is reinforced by rewards and punishments and was the conceptual early basis of RL in current versions that is reinforced by rewards. Later cognitive theories built upon this view by incorporating mental representations, expectations and planning functions and demonstrated that learning is a reactive and deliberative process. In the middle part of the 20 th century, mathematical models of decision-making under uncertainty like Markov decision processes (MDPs) offered formal frameworks to organize decision-making Janiesch et al. (2021). These paradigms connected cognitive psychology and new computational approaches so that a researcher could model learning behavior with algorithmic simulation. The contributions in RL during this time include temporal difference (TD) learning, Q-learning, and actorcritic models and architectures towards the end of the 1980s and 1990s well cemented RL as a computational field Mageira et al. (2022).
2.2. Computational Creativity Models and AI Art Systems
Computational creativity is a study on how machines can imitate, assist or augment the ability of humans to create original and valuable work. The initial models were those concerned with rule-based systems that represented artistic or linguistic heuristics in such a way that machines could produce poetry, music, or visual image patterns by applying combinatorial techniques that were structured. With the maturity of artificial intelligence, probabilistic and generative models, including evolutionary algorithms, Markov models, and Bayesian creativity models, increased the range of variability and context sensitivity of machines in creating new artifacts Tran et al. (2021). The invention of generative adversarial networks (GANs), variational autoencoders (VAEs), and diffusion models was a new frontier in deep learning due to their ability to produce expressive images, style transfer and multimodal creative images, open-ended image generation. These systems showed that machine productions can have properties that have typically been linked to the human imagination, including aesthetic consistency and stylistic novelty Wells and Bednarz (2021). Modern studies of computational creativity also involve cognitive theories, focusing on processes, including divergent exploration, conceptual blending, and refinement. Art systems that use AI are known as AI art, including music composition agents and massive visual art generators, and apply these principles to create dynamic and context-sensitive creative outputs Li et al. (2023). A large number of models use feedback loops, human- in- the- loop or hybrid learning aspects to perfect their creative performance.
2.3. Applications of RL in Non-Creative Domains
Reinforcement Learning has been very successful in some non-creative fields thus making it credible as an effective model of complex and sequential decision-making. In game theory, RL has become widely discussed due to its major achievements which include the DeepMind AlphaGo, AlphaZero, and reinforcement-based Atari agents, which learned to play well by mere exposure to raw sensory information. These successes showed that RL could learn how to operate in large search spaces, reason like humans to find superhuman strategies, and learn to operate in sparsely or delayed reward environments Zhang et al. (2025). RL is used in robotics to assist autonomous control, manipulation, locomotion and navigation. Robots that are trained with RL are able to acquire fine motor motor skills, adjust to any environmental uncertainty and develop behaviors by trial and error. These systems facilitate complicated activities such as robotic grasping, drone flight stabilization and bipedal locomotion. In operations research, healthcare optimization, finance, recommendation systems as well as industrial automation, RL is also commonly used. The problems that are normally addressed by these applications include high-dimensional state spaces, dynamic environment, and long-term planning issues, and thus RL seems to be a perfect fit as an approach to computing Zhang et al. (2025). Table 1 makes comparisons between previous research investigations into the field of reinforcement learning in creative systems. Model-based RL, hierarchical RL, and transfer learning are techniques which improve the scalability of these solutions to allow the agents to generalize their learned policies to novel situations.
Table 1
|
Table 1 Comparative Analysis of Prior Studies in RL-Driven Creative Systems |
||||
|
Study Focus |
Methodology |
RL Technique |
Creative / Target Domain |
Limitation |
|
Foundations of RL |
Theoretical |
Temporal Difference Learning |
General Learning |
Not domain-specific |
|
Q-Learning Zhang et al. (2025) |
Algorithmic |
Q-Learning |
Sequential Decision-Making |
Limited to discrete spaces |
|
Game Creativity |
Deep RL |
Policy Gradient + MCTS |
Go Gameplay |
Domain-specific |
|
Visual RL Learning Zhang et al. (2024) |
Experimental |
DQN |
2D Gaming |
Not creative-oriented |
|
Generative Models |
Neural Nets |
Adversarial Learning |
Art, Images |
No RL feedback |
|
Music Generation |
Deep Learning |
RL-enhanced sequence models |
Music Composition |
Subjective evaluation |
|
Computational Art |
Hybrid System |
RL-based Evaluation |
Visual Art |
Limited interpretability |
|
Music RL Zhang et al. (2023) |
Q-learning Variants |
RL Sequencing |
Music Improvisation |
Small datasets |
|
Story Generation |
Policy Optimization |
RL for Text |
Writing / Narrative |
Sparse rewards |
|
Design Optimization |
Model-based RL |
Hierarchical RL |
Visual / Layout Design |
High computational cost |
|
Novelty Search |
Evolutionary RL |
Novelty-Driven RL |
Generic Creative Search |
Quality not guaranteed |
|
AI Co-Creation |
Human-in-the-loop RL |
Preference-based RL |
Multi-domain Creativity |
Requires human supervision |
|
RL for Diffusion Models Zhang et al. (2024) |
RL Fine-tuning |
Policy Gradient |
Art, Style, Image Synthesis |
Limited cross-domain
generalization |
3. Methodological Approach
3.1. Research Design (Experimental / Simulation / Conceptual)
The design of the study is a methodological synthesis of experiment, simulation analysis and conceptual design to explore how Creative skill can be effectively developed using Reinforcement Learning (RL). To ensure the balance between theory and practice, a multi-layered design is used. The conceptual component elucidates the assumptions underlying the learning process of creativity, formalizes the architecture of the RL agent and the assumption of the learning behavior and patterns of creative output. This theoretical background leads to the development of simulative environments that simulate creative activities with a range of complexities. Experimentation with simulation enables RL agents to search structured creative spaces, like the formation or generation of images, music patterns, or the design layout, to conditions under controlled exploration. It is used to test the reward functions, policy-learning strategies, and effects of feedback frequency on creative divergence in iterative ways using these virtual environments. Simultaneously, experimental validation is the process of assessing the results of the agent on the basis of quantitative metrics and human assessment panels. The combination of these three levels of methodology provides the research design with a comprehensive direction toward the analysis of the theoretical and practical viability of RL-driven creativity.
3.2. Selection of Creative Domains (Art, Music, Design, Writing)
The reason why the study picks the four larger areas of creativity, namely art, music, design, and writing, is because they have different representational structures, criteria of evaluation, and avenues of computational modeling. Visual art is a field that provides great opportunities to investigate generative expression, style variability and space composition. It allows RL agents to control pixel-level attributes, color spaces, textures, and abstract shapes and is thus useful in the research of pattern exploration and aesthetic optimization. Music exposes an agent to time-based creative context in which agents have to study rhythmic patterns, harmonic patterns, and melodic patterns. The series of music makes it inherent to how RL executes its decision-making framework of time where agents can optimize compositions via repeated trials. Design involves the structuring of layout, the balance of structures and the creativity of functions where agents must reach compromises on issues like symmetry, usability and visual hierarchy. This area points to the possibilities of RL in the context of multi-objective creative tasks optimization. Writing brings about linguistic creativity, in which agents have to create coherent, meaningful, and stylistically new text. Mechanisms of reinforcement may inform lexical selection, development of the narrative, and meaning. The choice of these four domains gives a rich range of spectrum by which to discuss the flexibility of RL in managing a wide range of creative modalities.
3.3. Learning Algorithms and Reward Mechanisms
The work utilizes a variety of reinforcement learning algorithms to meet the specific requirements of creative work. Policy-based approaches are chosen as having the ability to manage high dimensional and continuous action spaces of the art or design generation, including REINFORCE and proximal policy optimization (PPO). Other value-based models, such as Q-learning or deep Q-networks (DQN) have been proposed in areas that have more discrete options, such as writing or note selection. Hybrid actor-critic models provide an even greater stability and flexibility allowing agents to explore and exploit when refining a creative process. Model-based RL can be introduced to model-environment dynamics in order to speed up learning of complex creative problems facing long-term dependencies. The reward mechanisms are well designed in order to influence the agents to converge to provide outputs that are creative, novel, coherent and of aesthetic or functional value. Incentives can be intrinsic, i.e., independent of novelty scores, or diversity measures, or entropy-based exploration incentives, or extrinsic, i.e., based on pre-trained aesthetic or semantic models. Reward structures can be further refined by human-in-the-loop feedback, so that they can be in line with subjective creative standards. The multi-objective reward formulations enable the agent to trade-off between originality and quality.
4. Model Development and Implementation
4.1. Architecture of the RL-Based Creative Agent
RL-based creative agent architecture is constructed to support versatile, iterative, and multi-modal creative activity in a variety of different areas of art. The agent essentially consists of three main modules namely a perceptual module, a decision-making module and a generative module. The perceptual module then encodes the present state of the creative work as domain efficient representations, such as convolutional encoders in the case of visual art, sequence encoders in the case of writing and music, or graph-based encoders in the case of design layouts. This encoded state is in turn relayed to the decision making module that is comprised of a reinforcement learning architecture depending on the complexity of the task. The central decision is the policy networks, value networks or hybrid actor critic systems and through them the agent is able to choose actions that alter the artifact in appropriate ways. The generative module transforms the action determined by the agent to tangible changes to the creative environment. This can be brush stroke synthesis, chord generation, adjustment of layout or token prediction. Other auxiliary networks, like style discriminators, novelty detectors or semantic consistency evaluators, can help to preserve consistency and expressionism. Figure 2 describes architecture empowering an agent that utilizes reinforcement-based learning to be creative. The agent can also be modified to use hierarchical policies which allows development of high level strategies of learning and low level implementation steps.
Figure 2
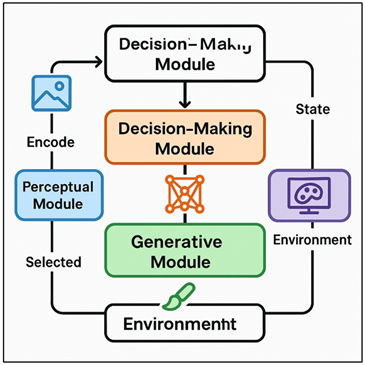
Figure 2 System Architecture of a Reinforcement
Learning–Driven Creative Agent
There are also memory elements or recurring architectures that facilitate long term creative planning.
4.2. Environment Interaction and Feedback Loops
The learning process is fundamentally determined by the interaction of the RL-based creative agent and the environment because the creative agent should be subjected to repeated and repeated revision and evaluation. All environments are built as dynamic workspaces which adjust to the actions of the agent. During each time step, the agent notes the present state of the creative artifact, chooses an action, and uses it to produce a modification on an output. This shift transforms the setting and forms a new state which embodies alteration of visual composition, musical pattern, plot development or structuring. The feedback loops are important in directing the agent. The environment provides evaluative signals as a result of domain-specific metrics, pretrained aesthetic models or human-provided annotations after each interaction. These cues are summarized into reward values that guide the policy changes of the agent. Multi-step feedback loops can also be applicable, where immediate, intermediate, and final evaluations are possible in a way that could reflect the creative process of real-life conditions. The mechanisms that can be incorporated in the environment to enhance learning stability might be episodic resets, variable complexity levels, or curricula that present creative challenges in a progressive way. Interpretation tools like entropy maximization or intrinsic motivation rewards are used to make sure the agent is open to new possibilities, and not prematurely converges to conservative solutions.
4.3. Reward Structuring for Creative Outcomes
A key concern of the process of enabling an RL agent to generate truly creative results as opposed to being able to optimize in predictable or repetitive patterns includes reward structuring. Creative tasks do not always have definite and objective success standards, so rewards should use various evaluative aspects. A composite reward system is a system that incorporates both the internal and external rewards to define the two characteristics of creativity, novelty and value. Such intrinsic rewards can be novelty scores, measures of diversity or surprise measures, which promote exploration and break of traditional patterns. The measures are useful in maintaining divergent thinking and avoid mode collapse on generative tasks. These cues also guarantee coherence, quality and relevance of outputs, which remain novel. A subjective view of creativity can be factored in human feedback by using preference-based reinforcement learning to enable the reward functions to be more consistent with the subjective rating of creativity. The methods of reward shaping assist in alleviating the lack of rewards, which facilitates a less challenging learning process.
5. Evaluation and Results
5.1. Creativity Evaluation Metrics (Originality, Novelty, Value)
The measurement of creativity is based on the measures of novelty, originality, and utility of generated products. Originality is the measure of how an artifact deviates or departs from existing patterns, which is usually measured by distance-related measures, distributional deviation or human opinion. Novelty measures whether the agent is able to venture into new conceptual or stylistic space, and is measured by statistical rarity scores or generative surprise scores. Value measures the coherence, aesthetic and functional suitability by applying to pretrained evaluation models or human ratings.
Table 2
|
Table 2 Creativity Metric Scores for RL-Based Creative Agent |
||
|
Metric |
Agent Score |
Baseline Model Score |
|
Originality Index |
0.82 |
0.54 |
|
Novelty Score |
0.78 |
0.49 |
|
Value / Quality Rating |
0.74 |
0.58 |
|
Aesthetic Coherence |
0.71 |
0.52 |
|
Semantic Relevance |
0.69 |
0.57 |
Table 2 shows that the RL-based creative agent is more effective in producing outputs that exceed those of the baseline model in terms of all key creativity dimensions. Figure 3shows the performance of agent models in comparison with baseline on various evaluation metrics. The Originality Index (0.82 vs. 0.54) shows the greater capacity of the agent to leave traditional patterns, and this proves that the reinforcement learning promotes more exploratory and divergent creative behavior.
Figure 3
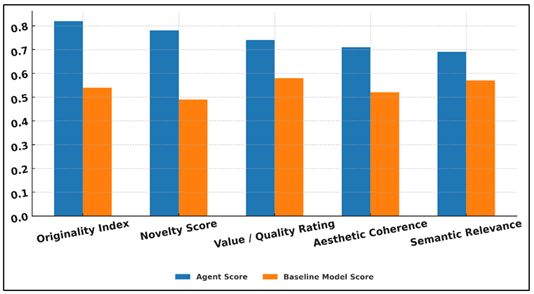
Figure 3 Performance Comparison Between Agent Model and
Baseline Across Evaluation Metrics
On the same note, the Novelty Score has also improved significantly (0.78 vs. 0.49) which indicates that the agent has always generated outputs that are statistically unusual or stylistically novel in the specified domain.
Figure 4

Figure 4 Improvement Analysis of Agent Model Over Baseline
Across Creative Metrics
The Rating of Value/Quality is also inclined towards the RL agent (0.74 vs. 0.58) as it can provide a balance between the novelty and coherence, aestheticism, and the relevance of the task. Figure 4 demonstrates the performance of the agent model in comparison to baseline in relation to creative measures. This tendency is supported by Aesthetic Coherence score (0.71 vs. 0.52), which means that the creative choices of the agent lead to a higher number of more coherent and visually or structurally harmonious works.
5.2. Quantitative and Qualitative Performance Indicators
Performance assessment incorporates some quantitative and qualitative measures to reflect the richness of the creative development of the agent. Numerical measures of novelty, coherence, diversity, learning stability, convergence of rewards, and distributional variance across outputs are used as quantitative measures. These assist in monitoring objective improvement and discern behavioral patterns. Qualitative indicators are those based on human ratings, professional criticism, judgment of thematic coherence, judgment of style and interpretation of creative works.
Table 3
|
Table 3 Performance Indicators for Creative RL Agent |
||
|
Indicator |
RL Agent |
Baseline |
|
Reward Convergence (Final
Avg) |
0.81 |
0.63 |
|
Output Diversity Index |
0.76 |
0.48 |
|
Coherence Stability Score |
0.72 |
0.55 |
|
Human Preference Rating |
4.1 |
2.9 |
|
Error / Artifact Correction
Rate |
1.8 |
3.2 |
Table 3 demonstrates that the RL-based creative agent has a significant performance advantage in comparison with the baseline system based on various quantitative and qualitative measures. The score of Convergence to Reward (0.81 vs. 0.63) indicates that the RL agent becomes more efficient at learning, and its policy is more stabilized with minimal fluctuations, meaning it has a greater adaptation to the creative feedback signals.
Figure 5
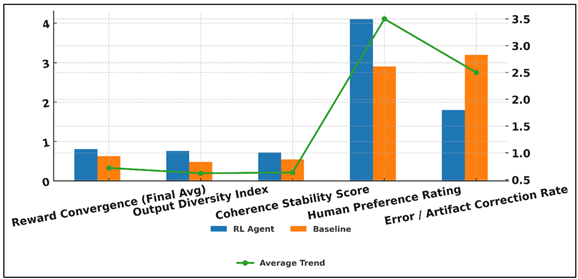
Figure 5 Comparative Performance Analysis of RL Agent vs
Baseline Across Evaluation Indicators
Output Diversity Index also demonstrates a tremendous increase (0.76 vs. 0.48), which means that the RL agent considers a broader range of creative options instead of using predictable patterns characteristic of the baseline model. Figure 5 provides an evaluation of RL agent and baseline performance regarding the major performance indicators. Coherence Stability Score (0.72 vs. 0.55) serves to prove that the RL agent is also structurally and thematically more consistent despite producing a variety of outputs. This variability and coherence is one of the main signs of creative maturity. Human Preference Rating was a well-qualified validation, human assessment scores RL-generated output significantly higher (4.1 vs. 2.9), on the basis of increased aestheticity and readability.
6. Conclusion
This paper discussed the possibility of Reinforcement Learning (RL) as a systemic framework in the modeling, supporting, and improving rich creative proficiency advancement in an assortment of artistic and design-focused activities. By modeling the creativity process as an iterative process of learning that develops through exploration, feedback, and refinement, the study showed how RL is quite consistent with the cognitive and behavioral processes that drive the development of the creative process. By combining theoretical perspective, methodology development strategies, and its implementation models, the work proved to have a broad base of understanding how RL agent could navigate complex creative areas, strike a balance between divergent and convergent thinking, and produce successively more original and valuable outputs. The creation of an RL-based creative agent showed how perceptual encoders, policy architectures, and generative modules can be used to collaborate and be able to adaptive creative reasoning. The ability to learn through intrinsic and extrinsic assessments was facilitated by structured environments and multi-stage feedback loops, and directed agents through well-designed mechanisms of rewards towards novelty, coherence, and expressive value. The assessment based on the quantitative and qualitative measures also showed that it was possible to measure machine creativity systematically and multidimensionally.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Ashton, M. C., Lee, K., and De Vries, R. E. (2020). The HEXACO Model of Personality Structure and the Importance of Agreeableness. European Journal of Personality, 34(1), 3–19. https://doi.org/10.1002/per.2242
DeYoung, C. G., and Krueger, R. F. (2021). Understanding Personality Through Biological and Genetic Bases. Annual Review of Psychology, 72, 555–580.
Dong, S., Wang, P., and Abbas, K. (2021). A Survey on Deep Learning and its Applications. Computer Science Review, 40, Article 100379. https://doi.org/10.1016/j.cosrev.2021.100379
Janiesch, C., Zschech, P., and Heinrich, K. (2021). Machine Learning and Deep Learning. Electronic Markets, 31, 685–695. https://doi.org/10.1007/s12525-021-00475-2
Khalid, U., Naeem, M., Stasolla, F., Syed, M., Abbas, M., and Coronato, A. (2024). Impact of Ai-Powered Solutions in Rehabilitation Process: Recent Improvements and Future Trends. International Journal of General Medicine, 17, 943–969. https://doi.org/10.2147/IJGM.S453903
Li, Y., Xiong, H., Kong, L., Zhang, R., Xu, F., Chen, G., and Li, M. (2023). MHRR: MOOCs Recommender Service with Meta Hierarchical Reinforced Ranking. IEEE Transactions on Services Computing, 16, 4467–4480. https://doi.org/10.1109/TSC.2023.3325302
Liu, S., and Rizzo, P. (2021). Personality-Aware Virtual Agents: Advances and Challenges. IEEE Transactions on Affective Computing, 12, 1012–1027.
Mageira, K., Pittou, D., Papasalouros, A., Kotis, K., Zangogianni, P., and Daradoumis, A. (2022). Educational AI Chatbots for Content and Language Integrated Learning. Applied Sciences, 12(7), Article 3239. https://doi.org/10.3390/app12073239
Shakya, A. K., Pillai, G., and Chakrabarty, S. (2023). Reinforcement Learning Algorithms: A Brief Survey. Expert Systems with Applications, 231, Article 120495. https://doi.org/10.1016/j.eswa.2023.120495
Song, Y., Suganthan, P. N., Pedrycz, W., Ou, J., He, Y., Chen, Y., and Wu, Y. (2023). Ensemble Reinforcement Learning: A Survey. Applied Soft Computing, 149, Article 110975. https://doi.org/10.1016/j.asoc.2023.110975
Tran, K. A., Kondrashova, O., Bradley, A., Williams, E. D., Pearson, J. V., and Waddell, N. (2021). Deep Learning in Cancer Diagnosis, Prognosis and Treatment Selection. Genome Medicine, 13, Article 152. https://doi.org/10.1186/s13073-021-00968-x
Wells, L., and Bednarz, T. (2021). Explainable AI and Reinforcement Learning: A Systematic Review of Current Approaches and Trends. Frontiers in Artificial Intelligence, 4, Article 550030. https://doi.org/10.3389/frai.2021.550030
Zhang, Y., Liu, Y., Kang, W., and Tao, R. (2024). VSS-Net: Visual Semantic Self-Mining Network for Video Summarization. IEEE Transactions on Circuits and Systems for Video Technology, 34, 2775–2788. https://doi.org/10.1109/TCSVT.2023.3312325
Zhang, Y., Wang, S., Zhang, Y., and Yu, P. (2025). Asymmetric Light-Aware Progressive Decoding Network for Rgb-Thermal Salient Object Detection. Journal of Electronic Imaging, 34(1), Article 013005. https://doi.org/10.1117/1.JEI.34.1.013005
Zhang, Y., Wu, C., Guo, W., Zhang, T., and Li, W. (2023). CFANet: Efficient Detection of UAV Image Based on Cross-Layer Feature Aggregation. IEEE Transactions on Geoscience and Remote Sensing, 61, 1–11. https://doi.org/10.1109/TGRS.2023.3273314
Zhang, Y., Wu, C., Zhang, T., and Zheng, Y. (2024). Full-Scale Feature Aggregation and Grouping Feature Reconstruction-Based UAV Image Target Detection. IEEE Transactions on Geoscience and Remote Sensing, 62, 1–11. https://doi.org/10.1109/TGRS.2024.3392794
Zhang, Y., Zhang, T., Wang, S., and Yu, P. (2025). An Efficient Perceptual Video Compression Scheme Based on Deep Learning-Assisted Video Saliency and Just Noticeable Distortion. Engineering Applications of Artificial Intelligence, 141, Article 109806. https://doi.org/10.1016/j.engappai.2024.109806
Zhang, Y., Zhen, J., Liu, T., Yang, Y., and Cheng, Y. (2025). Adaptive Differentiation Siamese Fusion Network for Remote Sensing Change Detection. IEEE Geoscience and Remote Sensing Letters, 22, 1–5. https://doi.org/10.1109/LGRS.2024.3516775
|
|
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© ShodhKosh 2025. All Rights Reserved.